Reproducibility & Replicability
1 Principles of Clean Code
1.1 Why
Writing small scripts to solve toy programming puzzles is one thing, but writing a large amount of inter-connected code to analyse a dataset is quite another. What’s more organizing the data itself is something that can have a big impact on the organization and clarity of the code. It’s worth talking about and thinking about some basic principles for organizing data and code for realistic scenarios such as scientific experiments and data analysis work.
1.2 Principles
- code should work with zero (or extremely minimal) configuration by a newcomer
- it should be clear how to run the code, how the pieces of the code work together, and what the results are
- the more dependencies that exist in your code, the higher the probability that it will not work in the future (see Docker and related concepts for future-proofing a code base)
- code and the data it operates on should be packaged together and should “just work”
- data should be organized in files and folders with informative filenames and rational folder structures
- code should be clear so that others can understand how it works (and “others” includes you in the future)
1.3 Stages of Data Processing
Think about the stages of processing between raw data, intermediate data structures, and “final” data used for figures and statistical analyses.
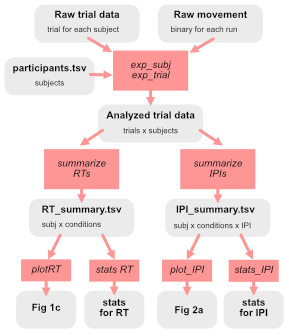
It should be crystal clear how to get each Figure or statistical analysis from data + code. Jörn suggests it and I agree: write out on a piece of paper what this directed graph looks like for your paper/project.
1.4 Code Accompanying a Paper
- code should reside in a publicly accessible repository (e.g. on GitHub)
- each Figure and each statistical analysis should be reproducible by running a single script/function without changes
- data should accompany the code
1.5 Code Sharing & Versioning Control
GitHub is a version control system and code-sharing platform that allows you to track changes to your code over time and collaborate with others. You can use GitHub to store and manage your code, data analysis notebooks, and even data (though not gigantic amounts of data), ensuring you can revert to previous versions if needed. GitHub works well with a number of other useful programs like Visual Studio Code and the online LaTeX document system Overleaf.
- Get Started with GitHub
- GitHub Skills
1.6 Readings
- Writing clean code guide from the Jörn Diedrichsen lab blog
- book: Clean Code: A Handbook of Agile Software Craftsmanship by Robert Martin
- a shorter book: A philosophy of software design by John Ousterhout, (and an accompanying website)
2 Plain-Text Document Processing
2.1 Why
Most of you have experience using programs like Microsoft Word to write papers and reports. The reason programs like these are so popular is that they are “what you see is what you get” (WYSIWYG) in their design. You see a graphical representation of the page, and of your document. Stylistic aspects like boldface, underlining, spacing, etc, are inserted using menus and buttons. MS Word and programs like it are easy to start using immediately. In many ways they mimic the typewriter (link for those of you who may not know what these ancient devices are)… you see a page, and you start typing.
There are however shortcomings of WYSIWYG programs like MS Word, especially for larger documents that include features like tables of contents, citations and bibliographies, figures and tables, etc. Technical documents that include mathematical equations can also be rather time consuming to generate in WYSIWYG word processors.
What is the alternative? There is another way of typesetting documents that involves separation of content and style. Content is specified using plain text, and then stylistic aspects are specified using markup (special keywords and codes).
One example of this style of document processing is HTML. Page content is specified using plain text, and stylistic aspects are specified using HTML tags (e.g. <br> for a line break, <div> to define a new section, <b> for boldface, <p> for a new paragraph, etc). Another example is CSS and how it works with HTML. An entire web site can be written in a generic way in HTML, and by referring to different CSS files, totally different stylistic presentations can be implemented. Another example is Markdown, in which simple markup tags can be used in a plaintext document to denote stylistic features. Markdown documents can be translated into HTML and several other formats using programs like pandoc. Another example, and the one that we will be looking at here, is called LaTeX (pronounced “lay-teck”).
2.2 Why not Microsoft Word? (a short diatribe)
Separating style and content frees your mind to focus on your thoughts, and writing, without constantly being taken out of the moment, to manually implement stylistic features of your document. If every time you start a new section, or compose a list, etc, you need to mentally pause your thoughts in order to find the menu or submenu element or ribbon-bar-button to enlarge the font, make it bold, insert bullet points, adjust spacing, etc, then that detracts from the continuity of your thoughts. In programs like MS Word, all of these stylistic aspects have to be implemented manually, throughout the document. In systems like LaTeX, style is specified separately from content, all in a single place, and so changing the look of your document can be done at a separate time from writing the content.
You all know, if you’ve ever written a large document like a scientific manuscript, that handling things like citations and bibliographies, figures, tables, equations, etc can be a huge nuisance. There are bibliography managers with citation features, such as EndNote, Zotero, and others, but in my experience they are rather difficult and unreliable to use. Imagine you are writing for a journal like Nature or Science, in which citations appear as numbers in increasing order as the document progresses. Imagine now you have 50 citations, and you decide that in the middle of your document, after citation #25, you need to add another one. Now you have to go through and manually change citations #26-50 to be 27-51. A similar issue exists with numbered equations, with Figures, and with Tables. Moving things around and you work on subsequent drafts of your article can often involve serious busywork in order to manually change citation, figure, equation, and table numbering.
In LaTeX, all of this is handled 100% automatically for you. At no point do you need to manually number citations, figures, equations, tables, sections, subsections, chapters, etc. These things are specified using LaTeX markup codes, and when you compile your LaTeX plaintext file (which generates a .pdf), all of the numbering is handled for you by the LaTeX system. This turns out to be a huge time saver, especially for long documents like a manuscript, or a thesis.
Side note: my PhD thesis (200+ pages) was written using LaTeX, and everything including citations, equations, figures, tables, sections, even a table of contents with page numbers, is generated automatically by LaTeX. What’s more, the thesis document itself is now > 25 years old, but I can still today compile it and generate a .pdf using the original LaTeX plaintext files.
Another reason why I like systems like LaTeX more than programs like MS Word is that Word files are encoded in a binary format, and are not immediately human-readable. To read a Word file one needs a program that knows how to open Word files. What’s more, Word file formats have changed over the years, and so there is no guarantee that some time in the future you will be able to easily open an old Word file. What’s more, different operating systems (Windows, Linux, Mac OSX) often are not 100% compatible and interchangable with respect to Word files. In contrast, systems like LaTeX use plain text ascii files. These are universally readable and 100% platform independent. ASCII files will be readable forever. LaTeX is also open-source and free, whereas MS Word is proprietary and licensed.
Have a look at the following sites to read more about the issue of Word vs LaTeX, and content vs style in document processing:
- Benefits of LaTeX typesetting
- Why LaTeX is superior to MS Word
- Why LaTeX? (plus more links at the bottom of the blog post)
- Five reasons you should use LaTeX and five tips for teaching it
- Sustainable Authorship in Plain Text using Pandoc and Markdown
- Why (and How) I Wrote My Academic Book in Plain Text
- Writing Technical Papers with Markdown
- Plain text, Papers, Pandoc
- How to ditch Word
2.3 What
- LaTeX
- Getting LaTeX (see bottom of page for instructions for Linux, MacOS, Windows)
- pandoc
- R Markdown
- Quarto
2.4 How
A few years ago I produced some introductory material for a plaintext_workshop I put on for interested profs and trainees in the Brain and Mind Institute at Western.
Here are some links to gentle introductions:
- An introduction to LaTeX
- LaTeX (wikibooks)
- Getting to Grips with LaTeX
- How to use BibTeX
- LaTeX Cheat Sheet (print this out and keep it handy)
I will openly admit that getting to know LaTeX involves somewhat of a learning curve. The best place to start is by looking at example templates and modifying them to suit your needs.
2.5 Overleaf
Overleaf is a collaborative, online LaTeX editor. They have a free tier and also a paid tier. The big advantage is that you don’t have to install LaTeX or maintain packages on your own computer. The disadvantage is that you don’t have LaTeX on your own computer.
They provide some good introductory tutorials for LaTeX. They also provide a large number of templates that you can launch and modify.
2.6 Quarto
- a guide to using Quarto to produce a wide range of documents
- getting started with Quarto
Quarto is a relatively new open-source scientific and technical publishing system, that uses plaintext markdown and/or jupyter notebooks to produce not just .pdf documents like reports and papers but also web pages, entire websites, interactive documents, books, and even presentations. I used Quarto to produce this course’s website as well as the website, notes, slides, homeworks, and exams, for my undergraduate statistics class Psychology 2812.
They have just released a new Quarto Manuscripts document type that looks interesting though I haven’t tried it yet.
3 Git & GitHub
coming soon …