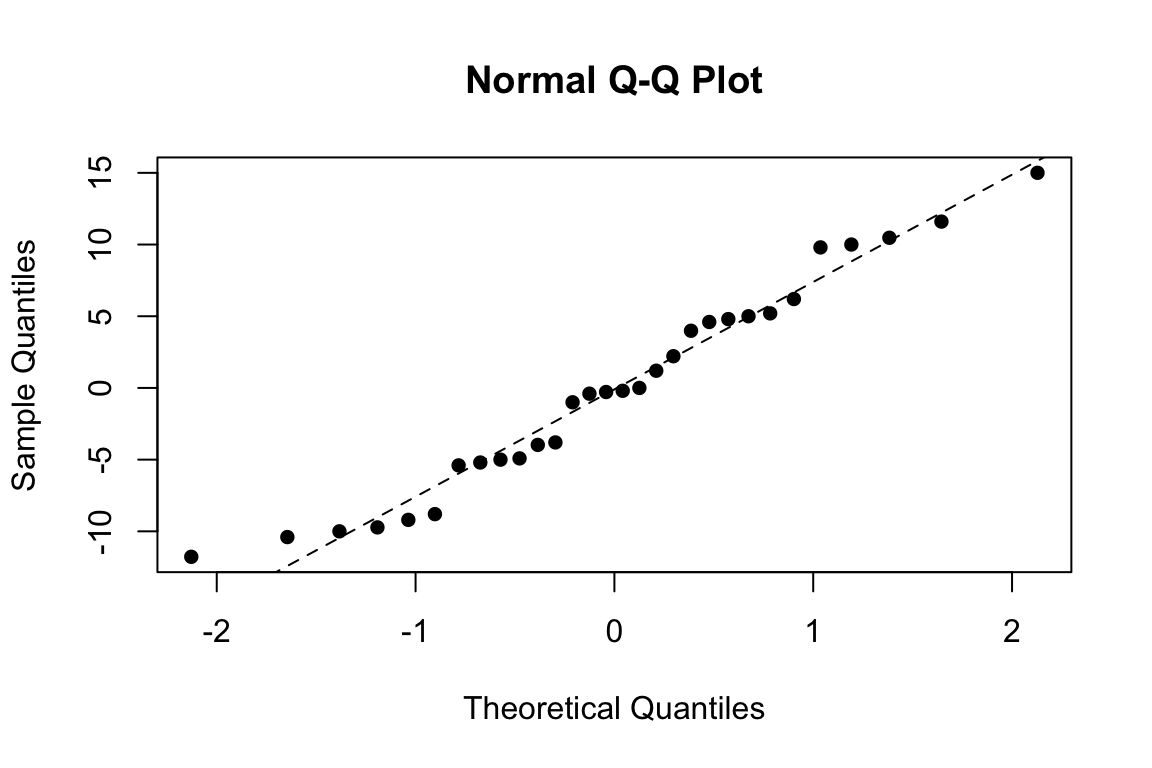
drug emmean SE df lower.CL upper.CL
absent 189 2.55 24 184 194
present 177 2.55 24 171 182
highdose 173 2.55 24 168 178
Results are averaged over the levels of: biofeedback
Confidence level used: 0.95
pairs(drugMM, adjust="tukey")
contrast estimate SE df t.ratio p.value
absent - present 12.5 3.61 24 3.464 0.0055
absent - highdose 15.9 3.61 24 4.406 0.0005
present - highdose 3.4 3.61 24 0.942 0.6199
Results are averaged over the levels of: biofeedback
P value adjustment: tukey method for comparing a family of 3 estimates
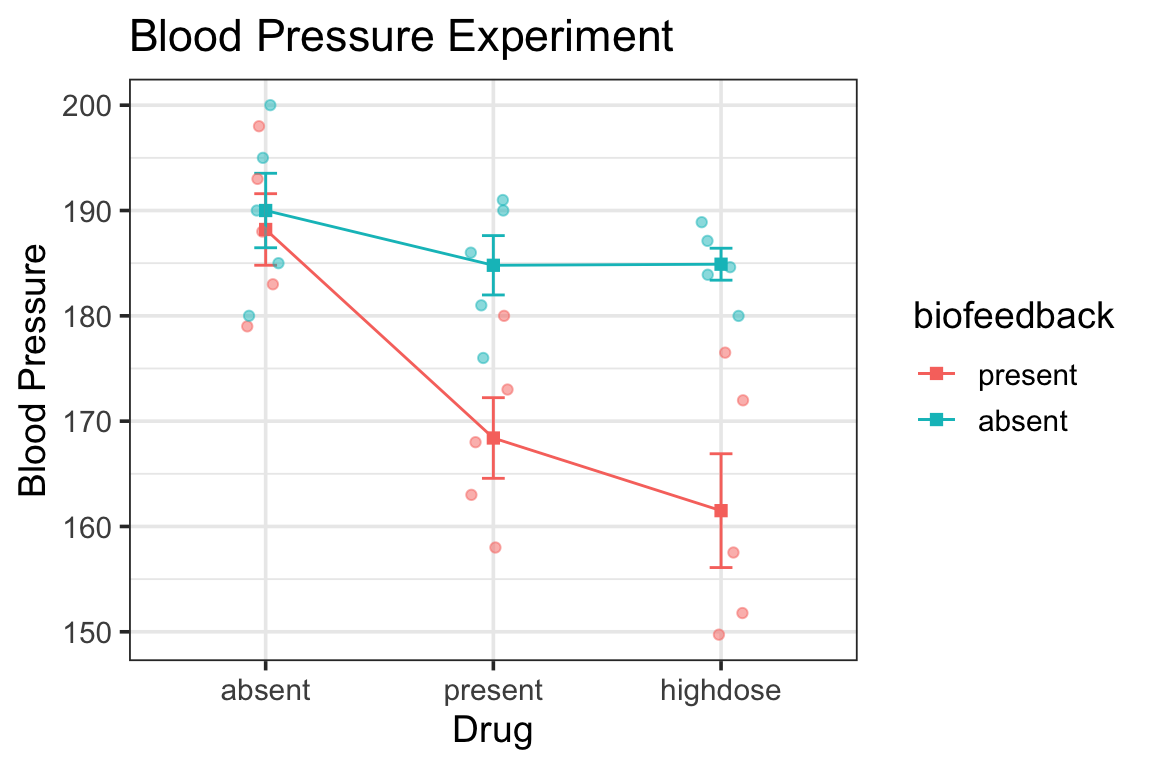
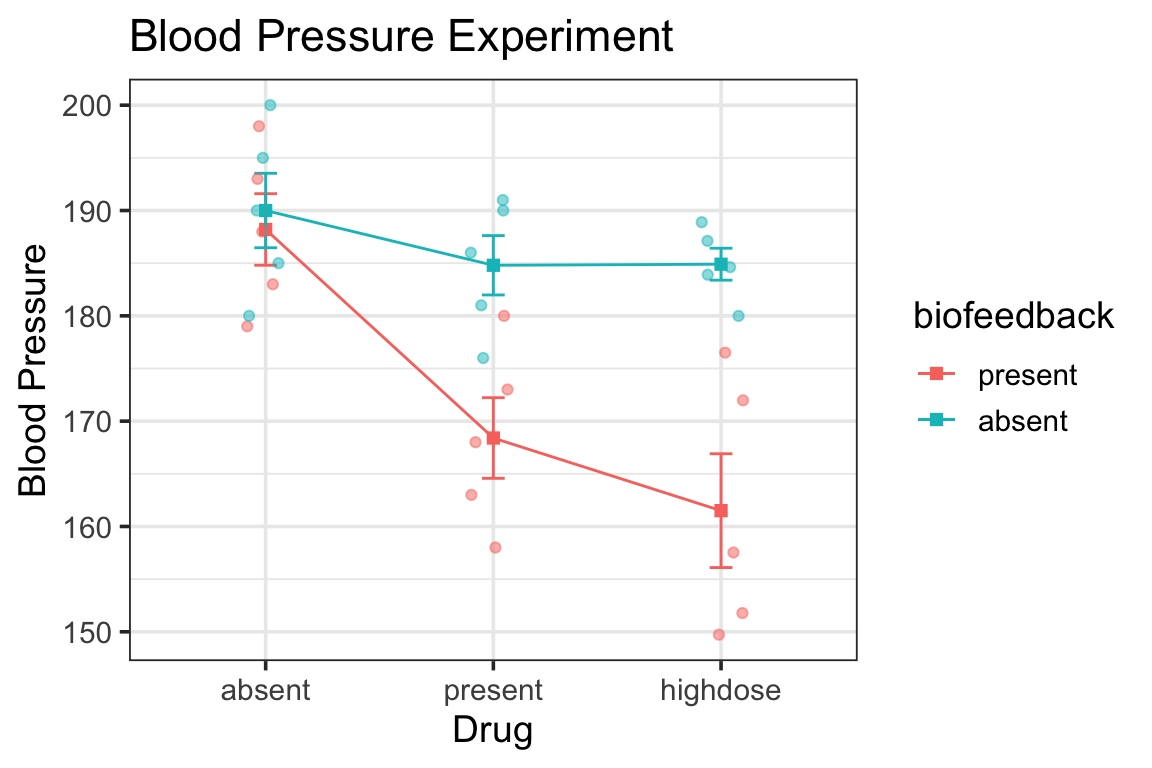
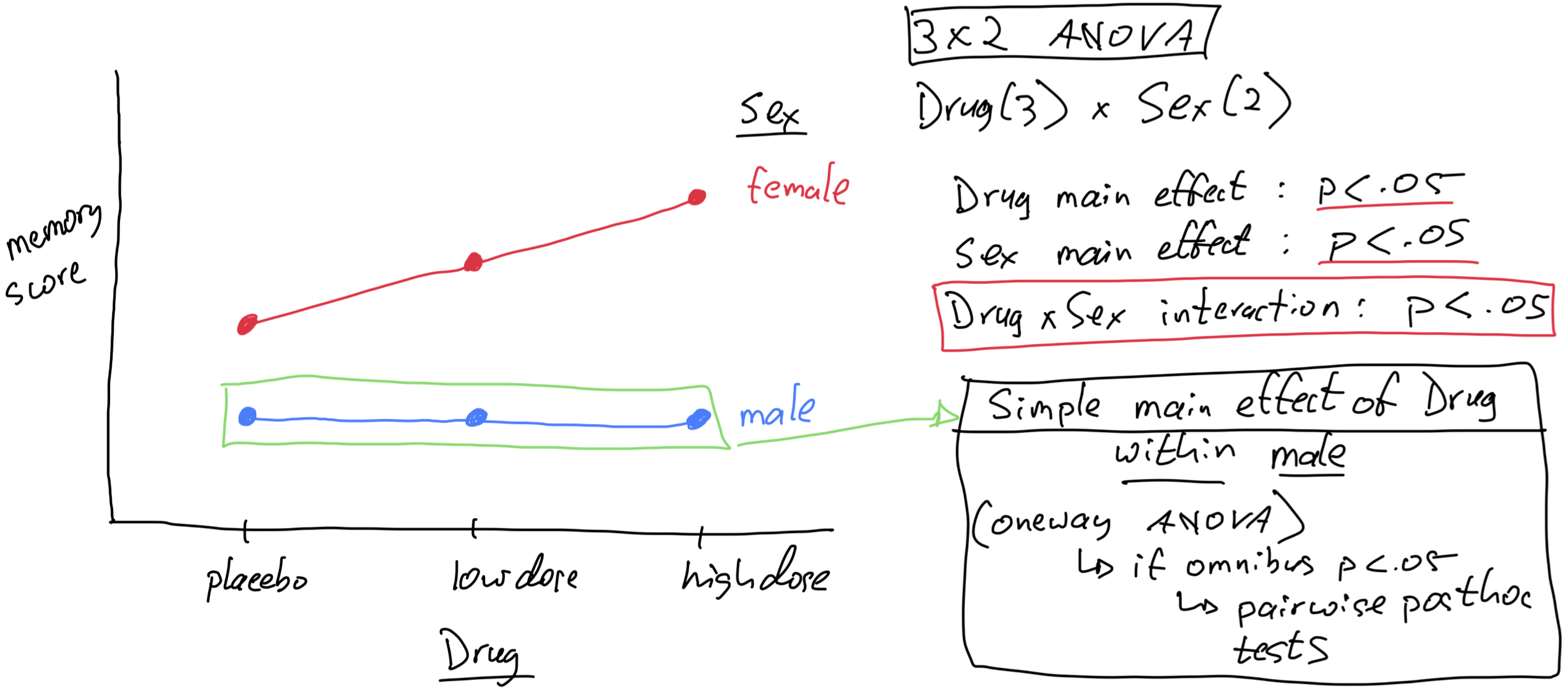
Following up a Main Effect in R
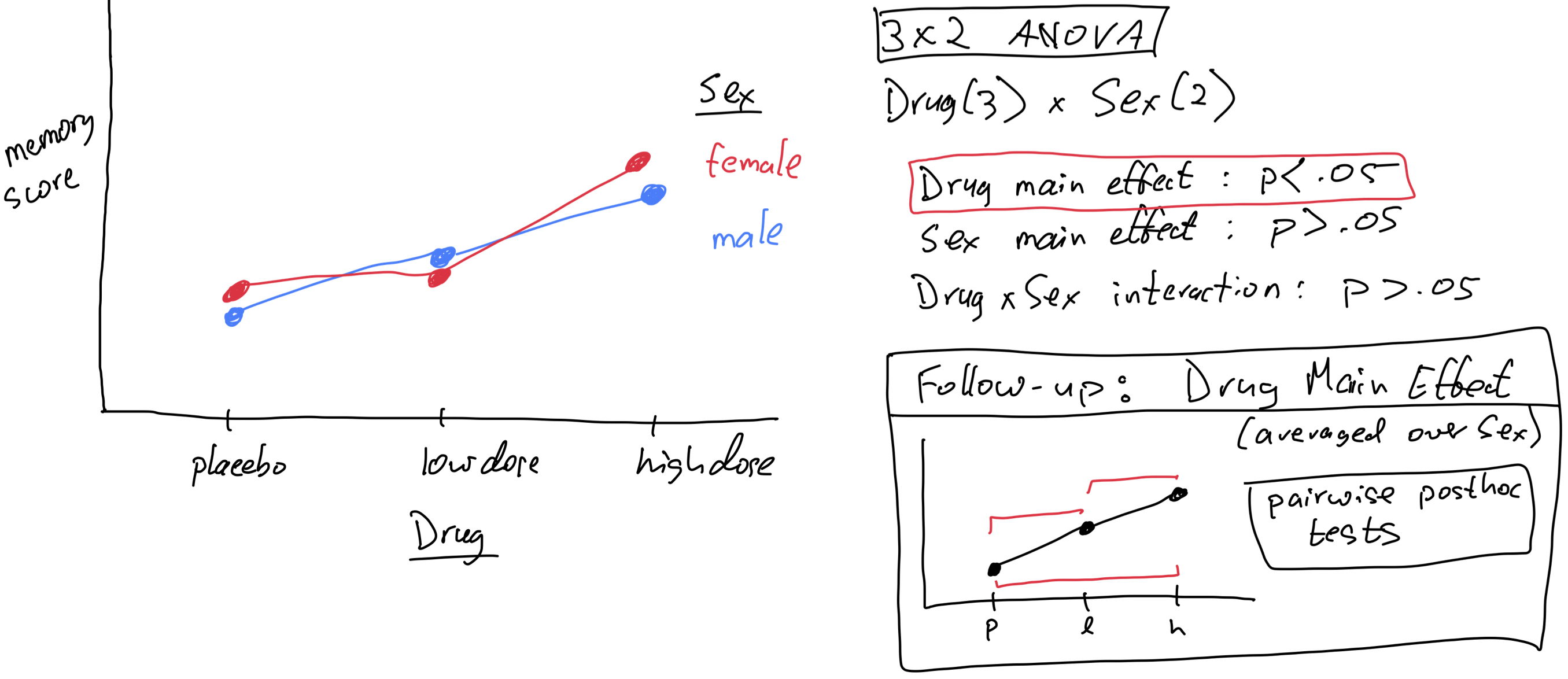
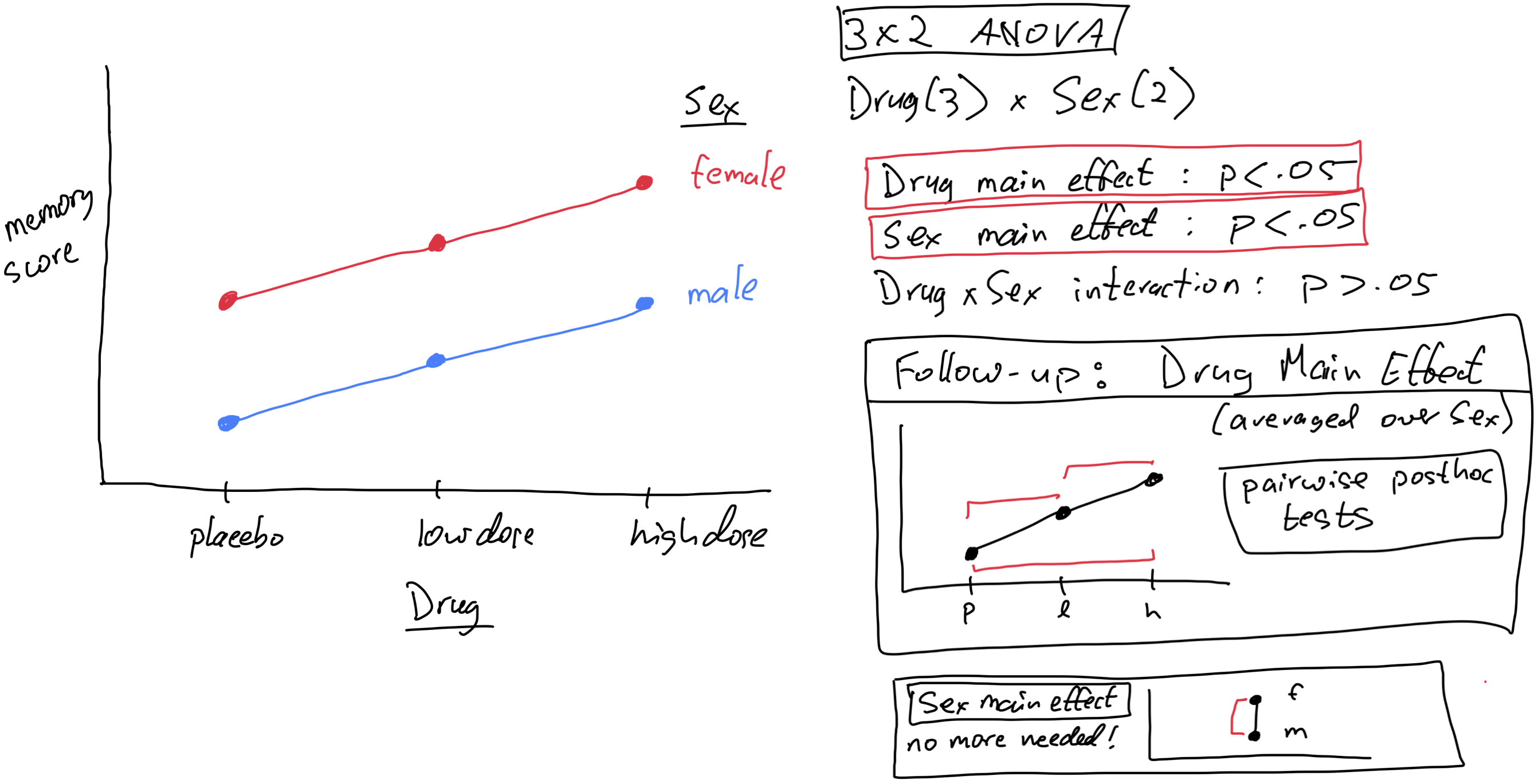
Df Sum Sq Mean Sq F value Pr(>F)
biofeedback 1 1442.2 1442.2 22.150 8.76e-05
drug 2 1401.8 700.9 10.765 0.00046
biofeedback:drug 2 607.3 303.6 4.664 0.01945
Residuals 24 1562.6 65.1
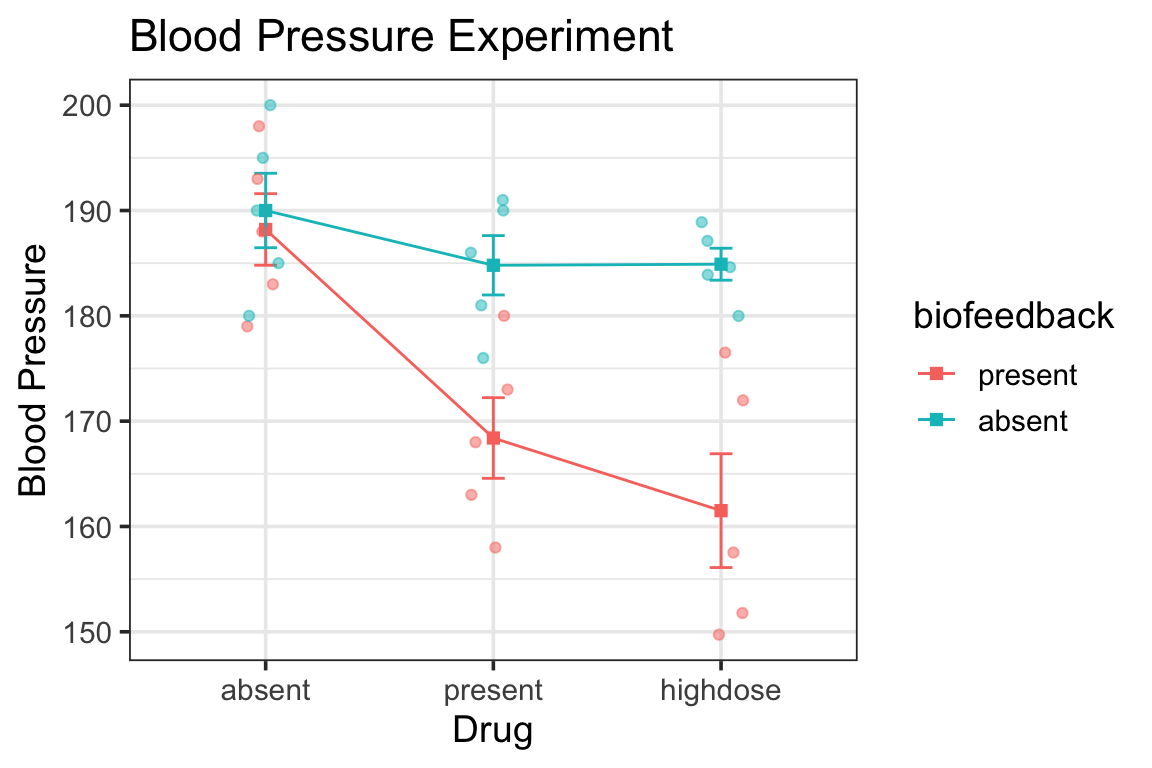
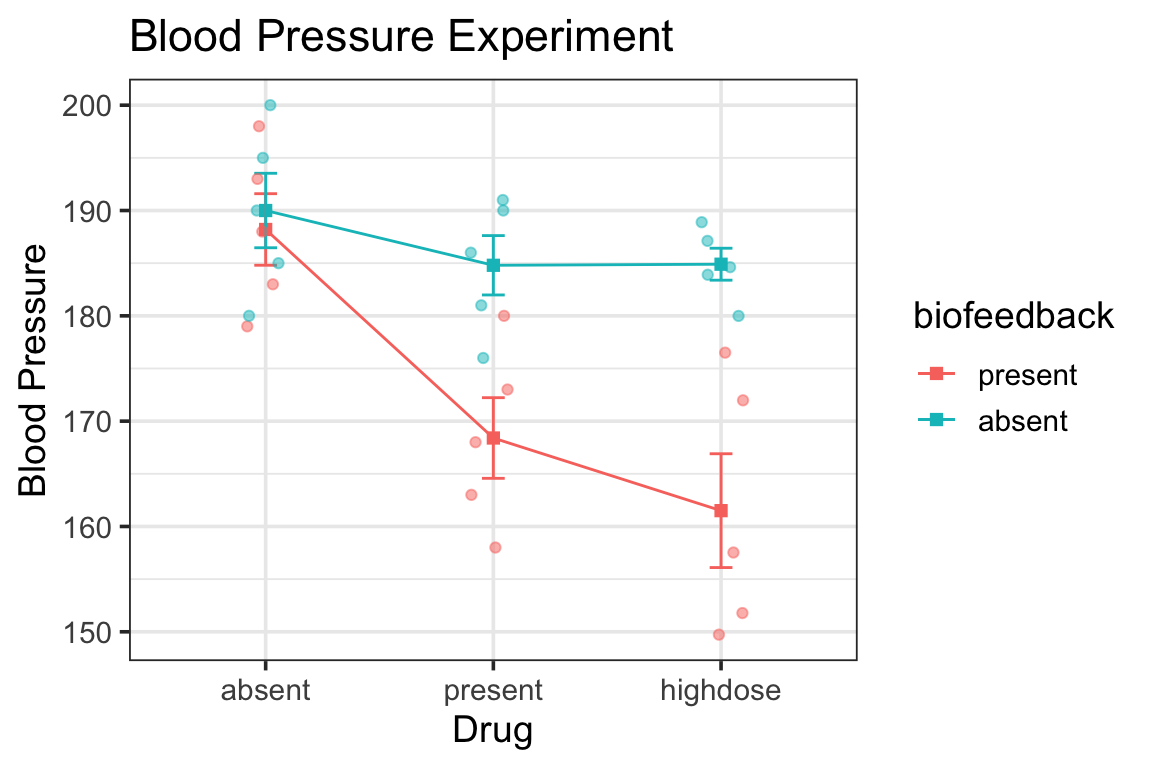
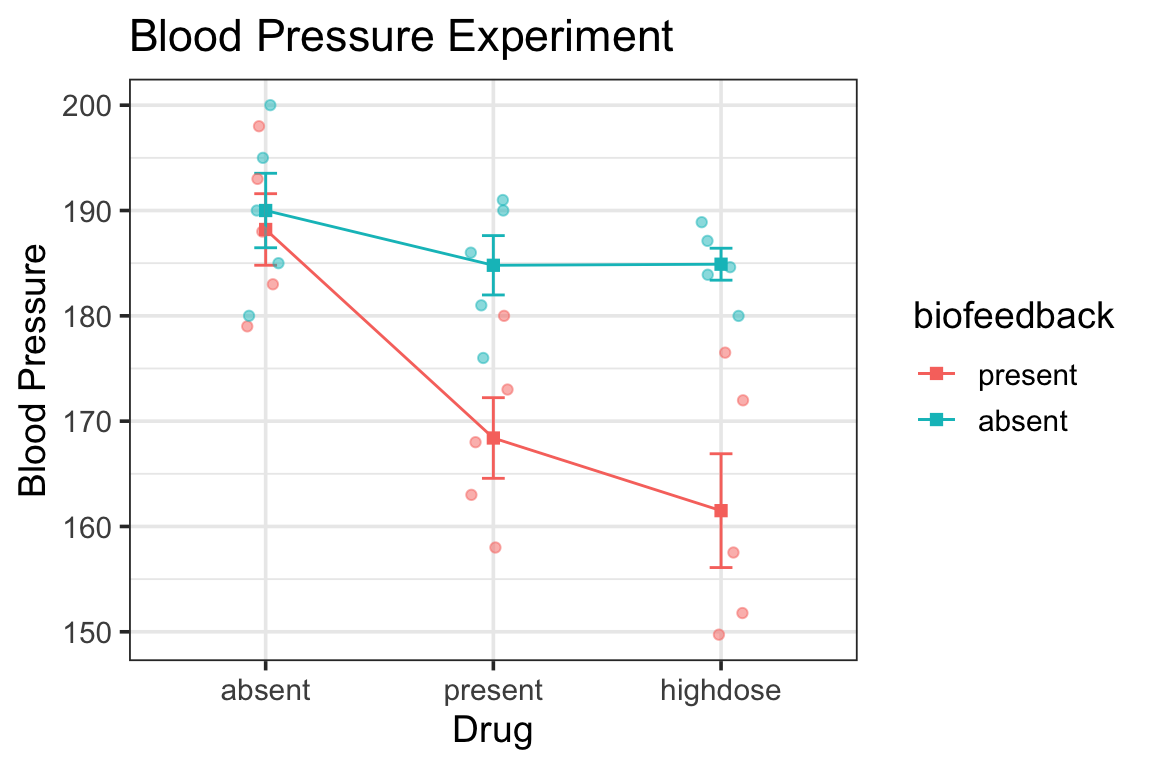
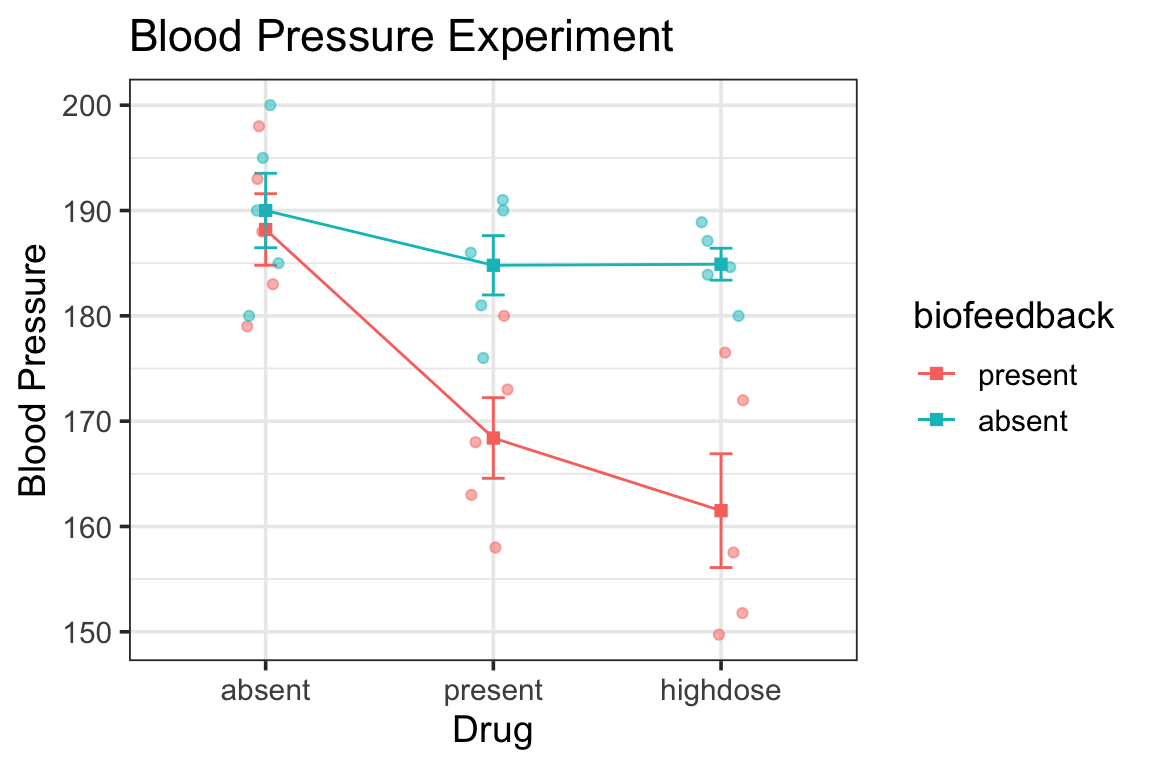
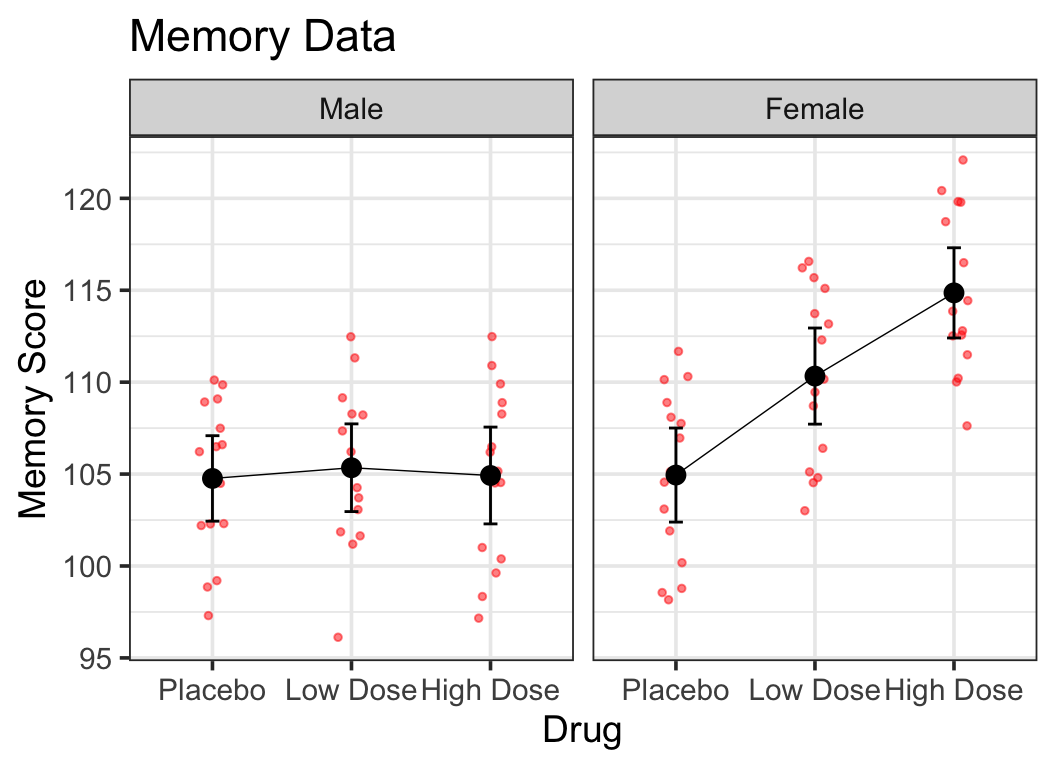
for purposes of demonstration let’s pretend for now that the biofeedback x drug interaction is not significant
contrast estimate SE df t.ratio p.value
absent - present 19.8 6.08 12 3.258 0.0137
absent - highdose 26.7 6.08 12 4.394 0.0026
present - highdose 6.9 6.08 12 1.135 0.2785
P value adjustment: holm method for 3 tests
Following up an Interaction in R
notice the ANOVA tables for the full ANOVA and for the simple main effect test:
summary(my.anova)
Df Sum Sq Mean Sq F value Pr(>F)
biofeedback 1 1442.2 1442.2 22.150 8.76e-05
drug 2 1401.8 700.9 10.765 0.00046
biofeedback:drug 2 607.3 303.6 4.664 0.01945
Residuals 24 1562.6 65.1
summary(present.anova)
Df Sum Sq Mean Sq F value Pr(>F)
drug 2 1921 960.3 10.4 0.0024
Residuals 12 1108 92.3
error term (Residuals) for full ANOVA is smaller than for simple main effect test
the Residuals df is way larger because it uses the whole dataset
the full ANOVA Residuals is also a more accurate estimate since it uses more data—it’s a pooled estimate of within-group variability
some researchers prefer to use the Residuals from the full ANOVA when performing simple main effects tests—a customized F-test using Residuals term from the full ANOVA
(F_sme <-960.3/65.1)
[1] 14.75115
(p_sme <-pf(F_sme, 2, 24, lower.tail =FALSE))
[1] 6.638425e-05
we end up with a larger F and a smaller p
it is a statistically more powerful test
Following up an Interaction in R
summary(my.anova)
Df Sum Sq Mean Sq F value Pr(>F)
biofeedback 1 1442.2 1442.2 22.150 8.76e-05
drug 2 1401.8 700.9 10.765 0.00046
biofeedback:drug 2 607.3 303.6 4.664 0.01945
Residuals 24 1562.6 65.1
summary(present.anova)
Df Sum Sq Mean Sq F value Pr(>F)
drug 2 1921 960.3 10.4 0.0024
Residuals 12 1108 92.3
a customized F-test using the Residuals from the full ANOVA
(F_sme <-960.3/65.1)
[1] 14.75115
(p_sme <-pf(F_sme, 2, 24, lower.tail =FALSE))
[1] 6.638425e-05
an argument against this approach is that when there is a possibility of a violation of homogeneity of variance, it is better to perform simple main effects tests on each subset of data (literally a one-way ANOVA on each subset of data)
this is because the pooled Residuals from the full ANOVA are not a good estimate of the error term for each subset of data
some researchers prefer the “one-way ANOVAs using subsets of the data” approach always, to avoid the possibility of inhomogeneity of variance affecting the results
Following up an Interaction in R
summary(my.anova)
Df Sum Sq Mean Sq F value Pr(>F)
biofeedback 1 1442.2 1442.2 22.150 8.76e-05
drug 2 1401.8 700.9 10.765 0.00046
biofeedback:drug 2 607.3 303.6 4.664 0.01945
Residuals 24 1562.6 65.1
contrast estimate SE df t.ratio p.value
absent - present 19.8 6.08 12 3.258 0.0137
absent - highdose 26.7 6.08 12 4.394 0.0026
present - highdose 6.9 6.08 12 1.135 0.2785
P value adjustment: holm method for 3 tests
Following up an Interaction in R
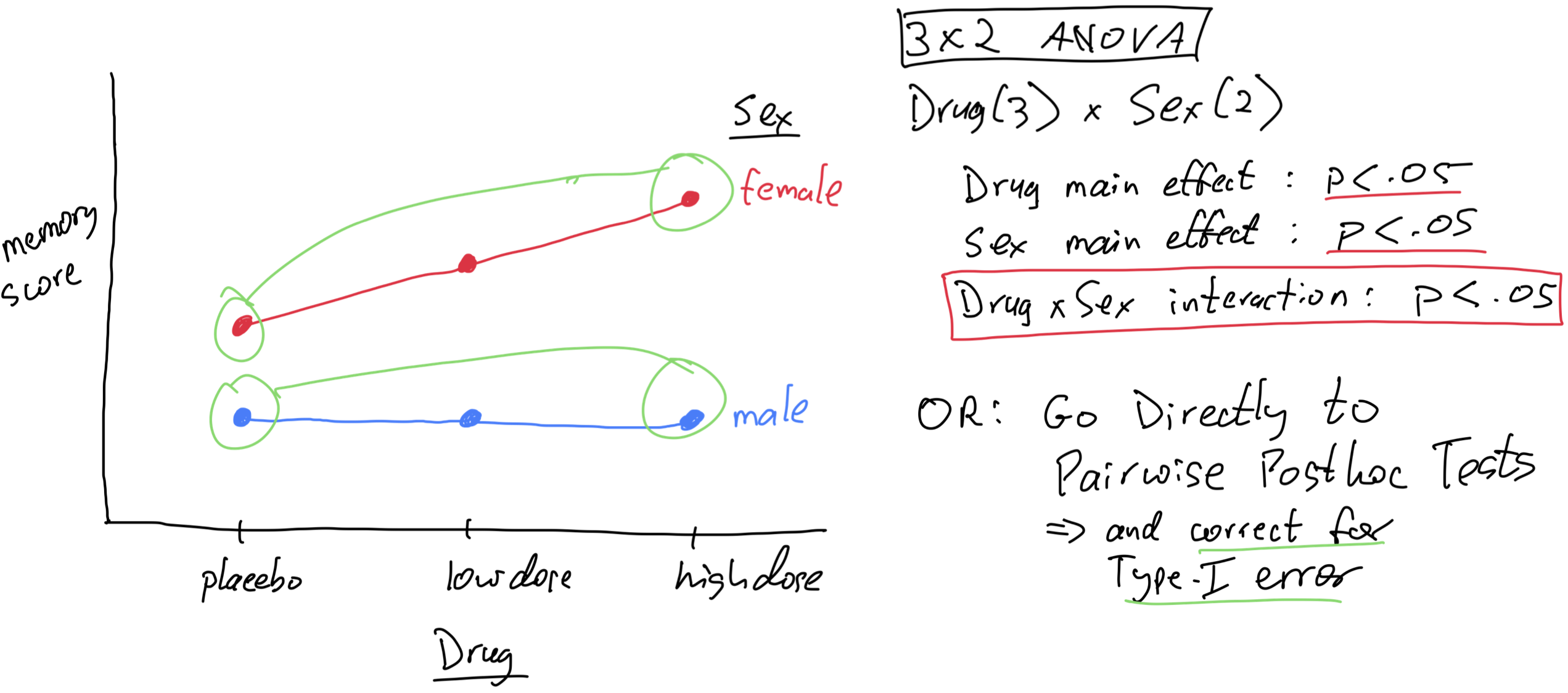
So what should you actually do?
should you do simple main effects tests?
should you use a “one-way ANOVA on each subset of data” approach?
or a custom F-test with numerator from one-way ANOVA and denominator from full ANOVA?
jump directly to pairwise tests?
using emmeans() and pairs() with adjust=...
Following up an Interaction in R
So what should you actually do?
the answer will depend upon many things
your own opinion about the best approach given your understanding of the tradeoffs
your research discipline’s conventions
your lab/supervisor’s conventions
pick an approach you believe in and understand how to defend/explain it
Following up an Interaction in R
So what should you actually do?
try your best to have a dataset such that it doesn’t matter which approach you take, the decision/conclusion will be the same (a nice position to be in)
Following up an Interaction in R
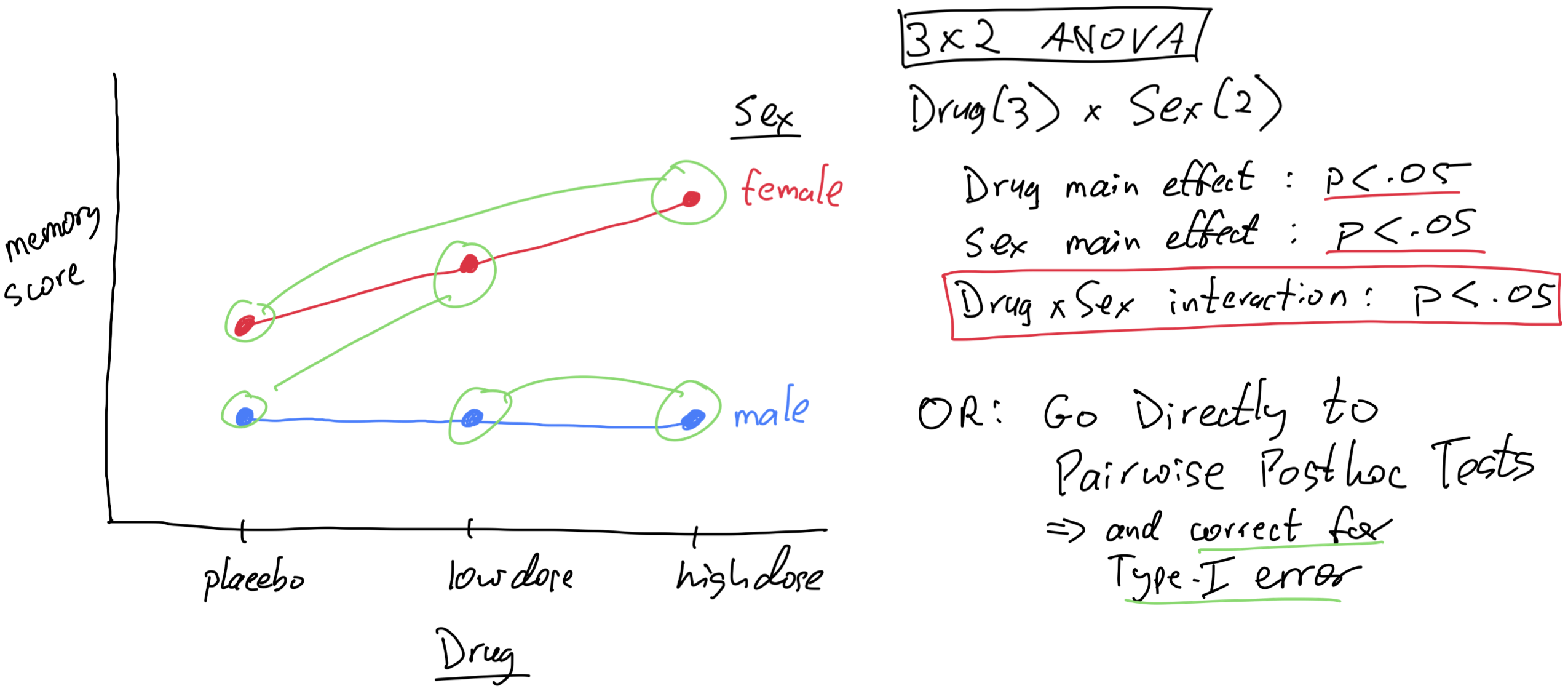
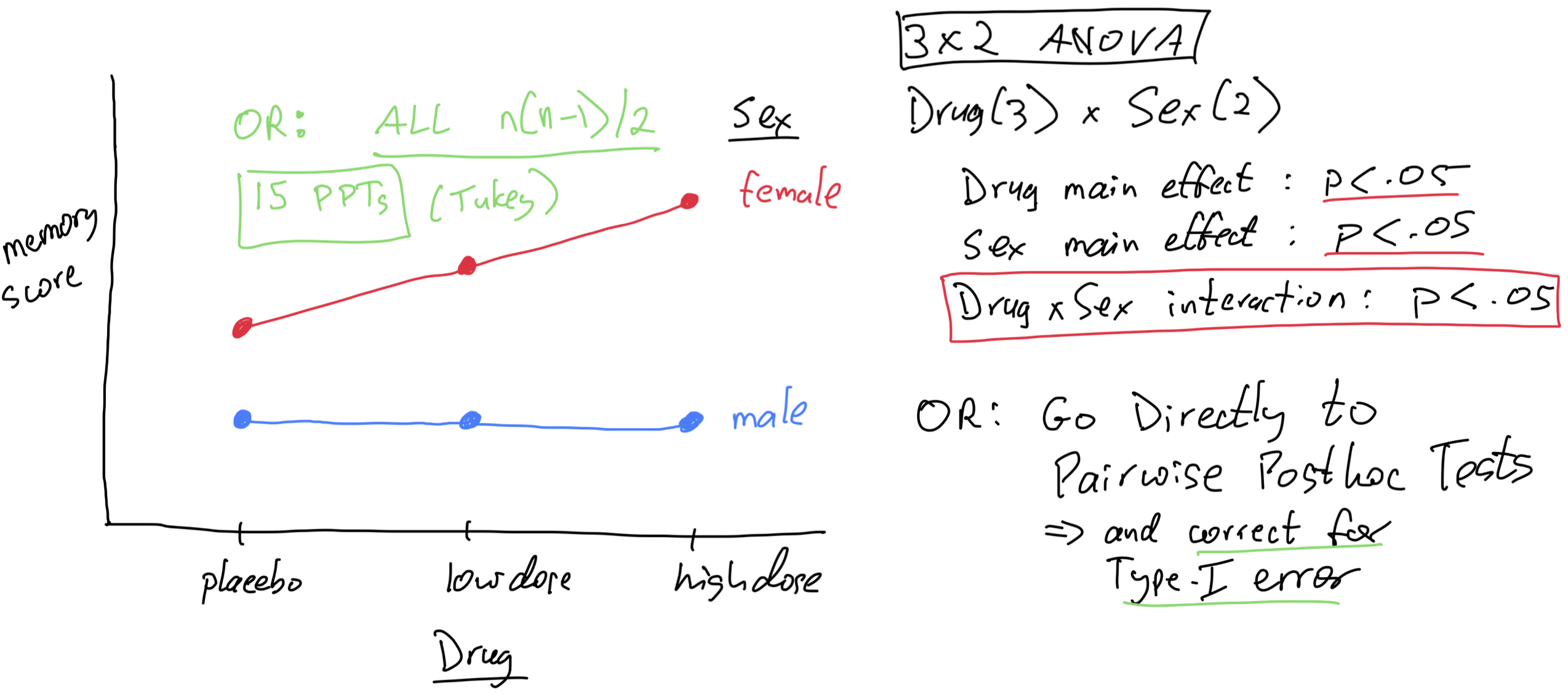
What do I do?
I jump directly to pairwise tests (corrected for Type-I error, usually with Holm’s method)
I believe the omnibus interaction test provides good initial protection from Type-I error, and this combined with the additional Type-I error correction used for the pairwise tests gives me good protection overall
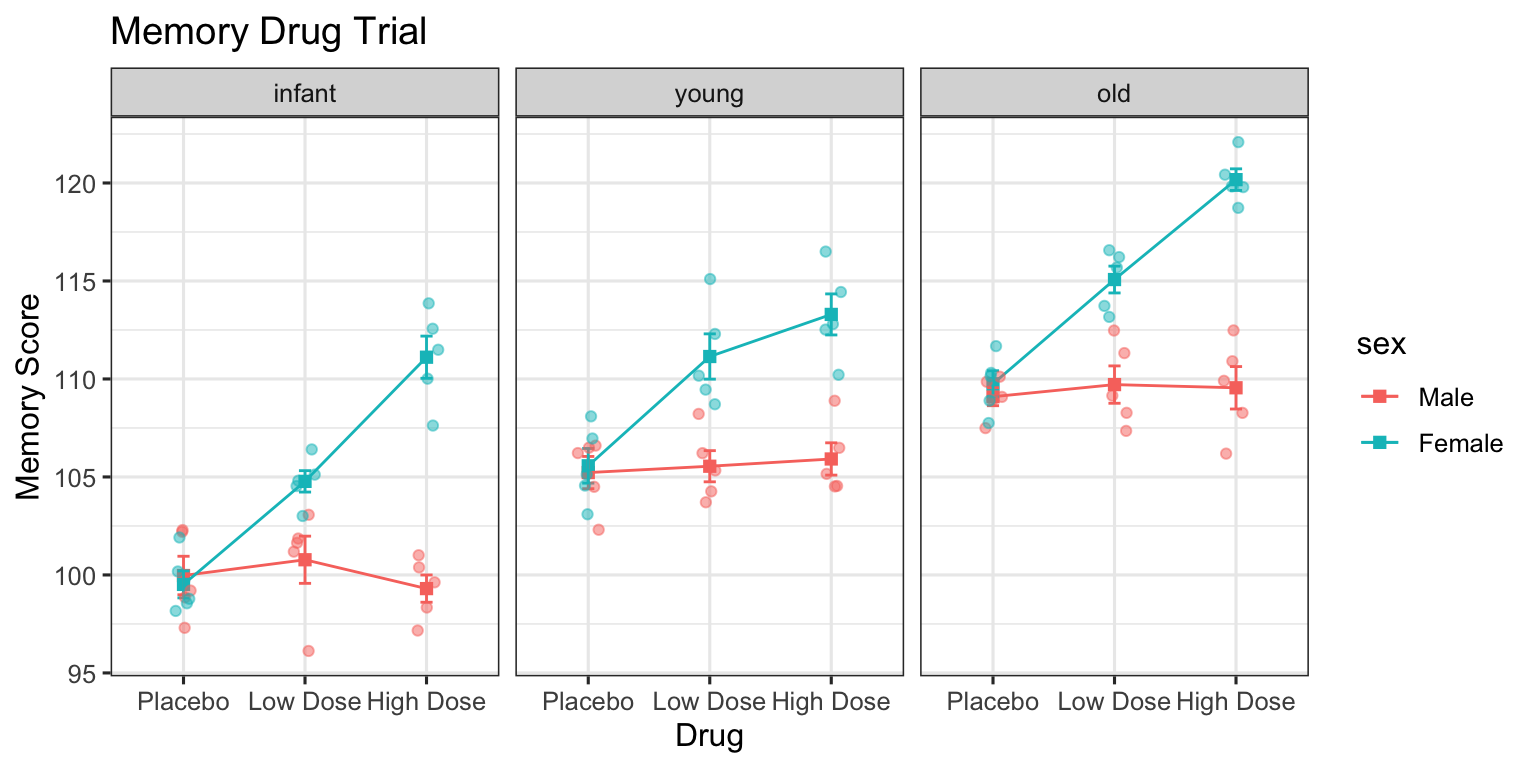
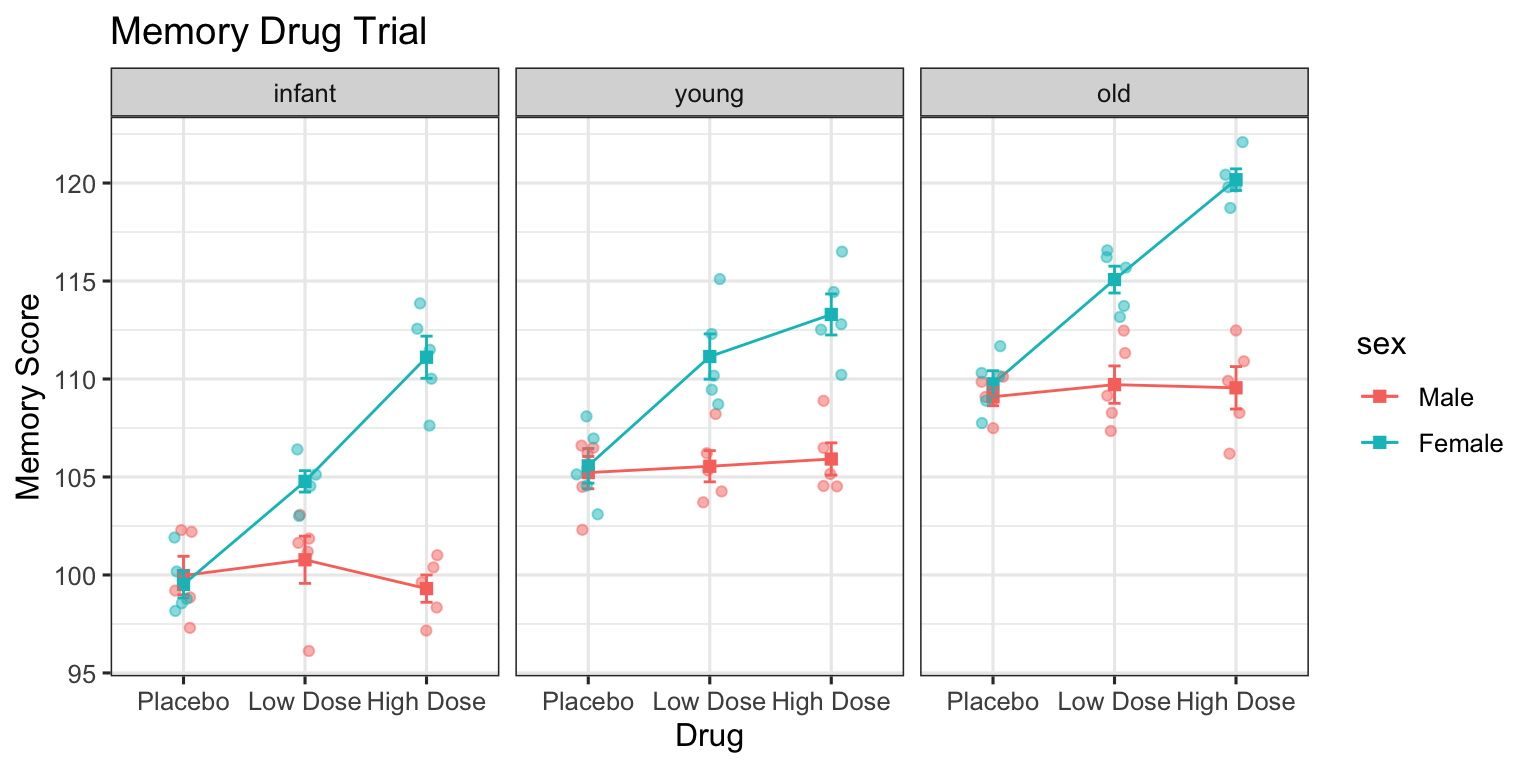
# A tibble: 18 × 6
# Groups: drug, sex [6]
drug sex age meanmem se n
<fct> <fct> <fct> <dbl> <dbl> <int>
1 Placebo Male infant 100. 0.982 5
2 Placebo Male young 105. 0.823 5
3 Placebo Male old 109. 0.459 5
4 Placebo Female infant 99.5 0.688 5
5 Placebo Female young 106. 0.884 5
6 Placebo Female old 110. 0.667 5
7 Low Dose Male infant 101. 1.20 5
8 Low Dose Male young 106. 0.795 5
9 Low Dose Male old 110. 0.953 5
10 Low Dose Female infant 105. 0.546 5
11 Low Dose Female young 111. 1.16 5
12 Low Dose Female old 115. 0.684 5
13 High Dose Male infant 99.3 0.696 5
14 High Dose Male young 106. 0.824 5
15 High Dose Male old 110. 1.08 5
16 High Dose Female infant 111. 1.08 5
17 High Dose Female young 113. 1.05 5
18 High Dose Female old 120. 0.551 5
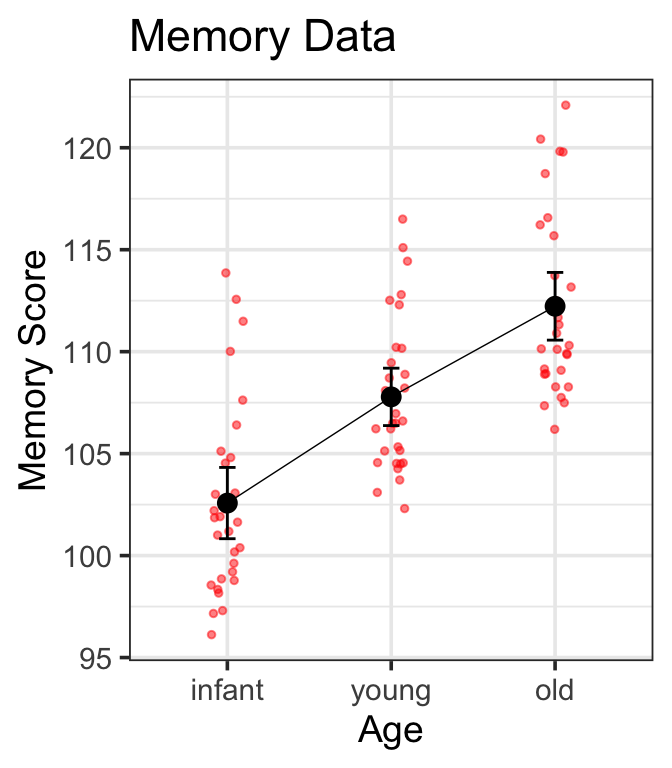
contrast estimate SE df t.ratio p.value
infant - young -5.21 0.501 72 -10.399 <.0001
infant - old -9.65 0.501 72 -19.273 <.0001
young - old -4.44 0.501 72 -8.874 <.0001
Results are averaged over the levels of: drug, sex
P value adjustment: holm method for 3 tests
there is a significant difference in memory score between the infant and young groups, t(72)=-10.4, p<.0001
there is a significant difference in memory score between the infant and old groups, t(72)=-19.3, p<.0001
there is a significant difference in memory score between the young and old groups, t(72)=-8.9, p<.0001
age emmean SE df lower.CL upper.CL
infant 103 0.354 72 102 103
young 108 0.354 72 107 108
old 112 0.354 72 112 113
Results are averaged over the levels of: drug, sex
Confidence level used: 0.95