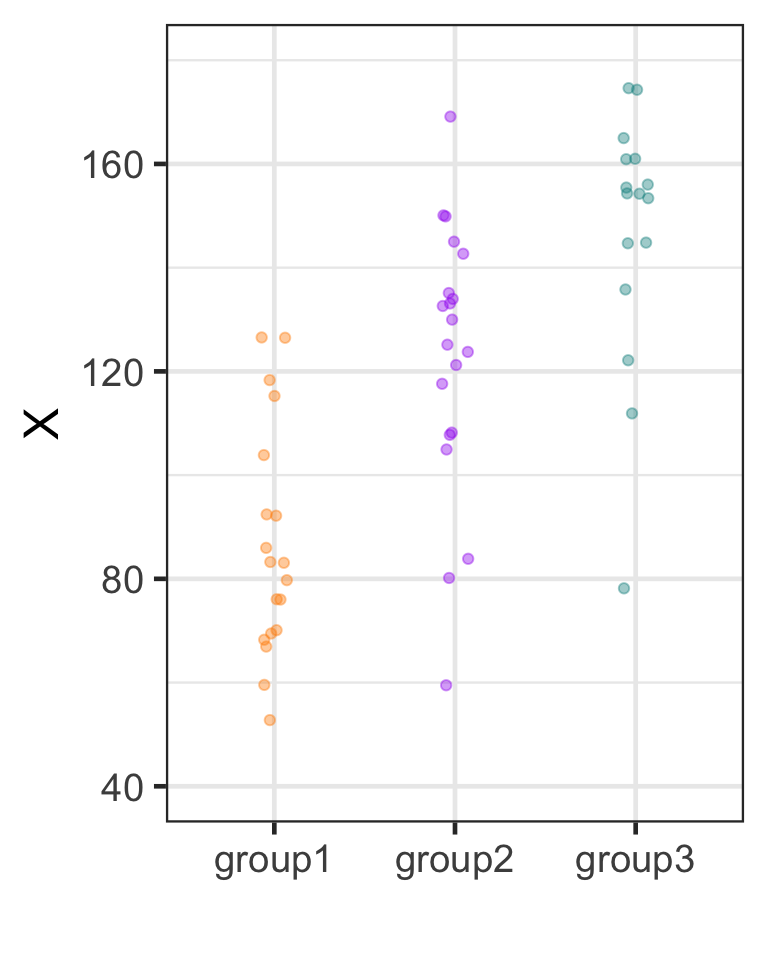
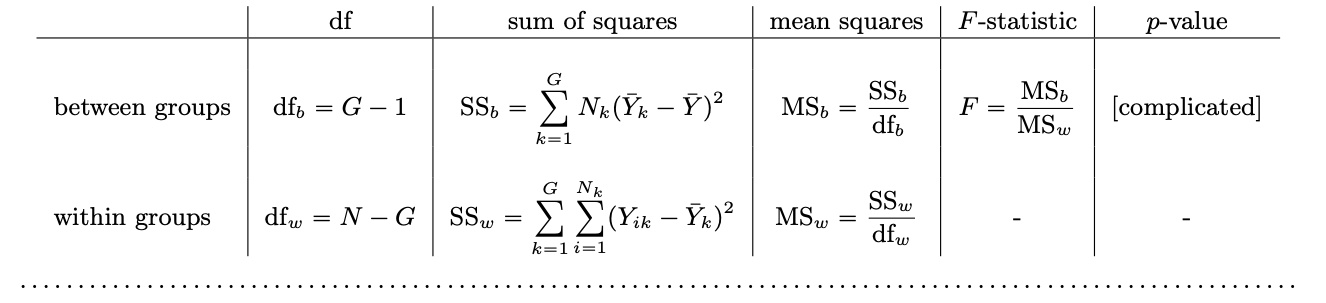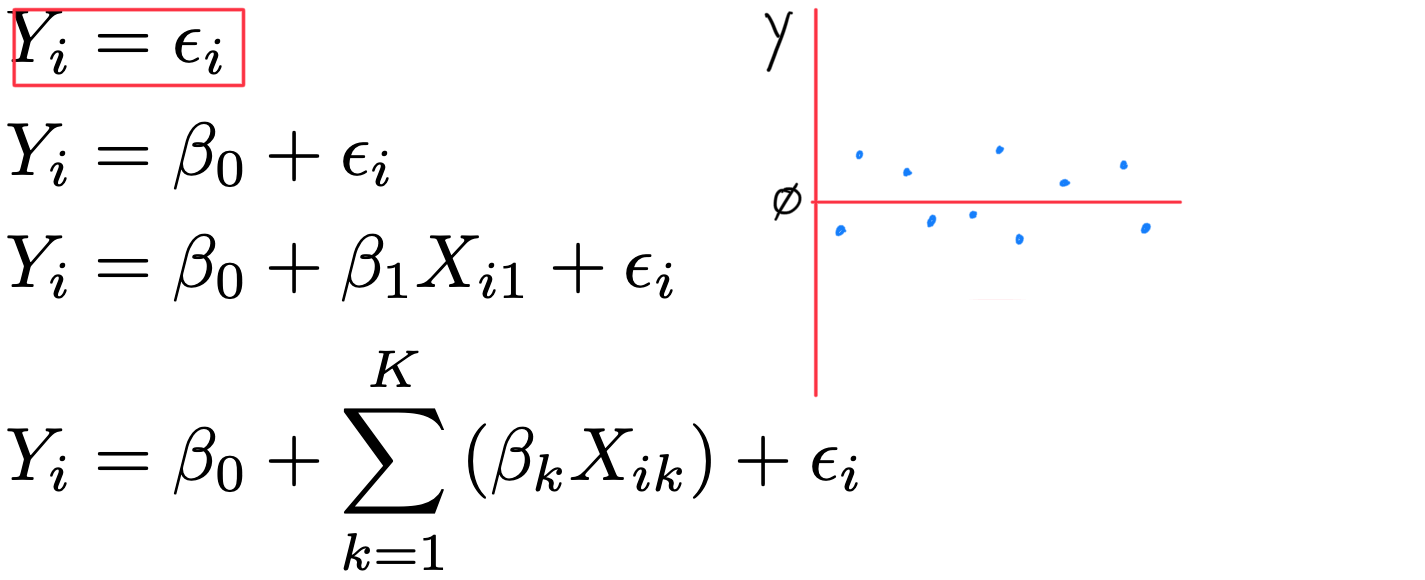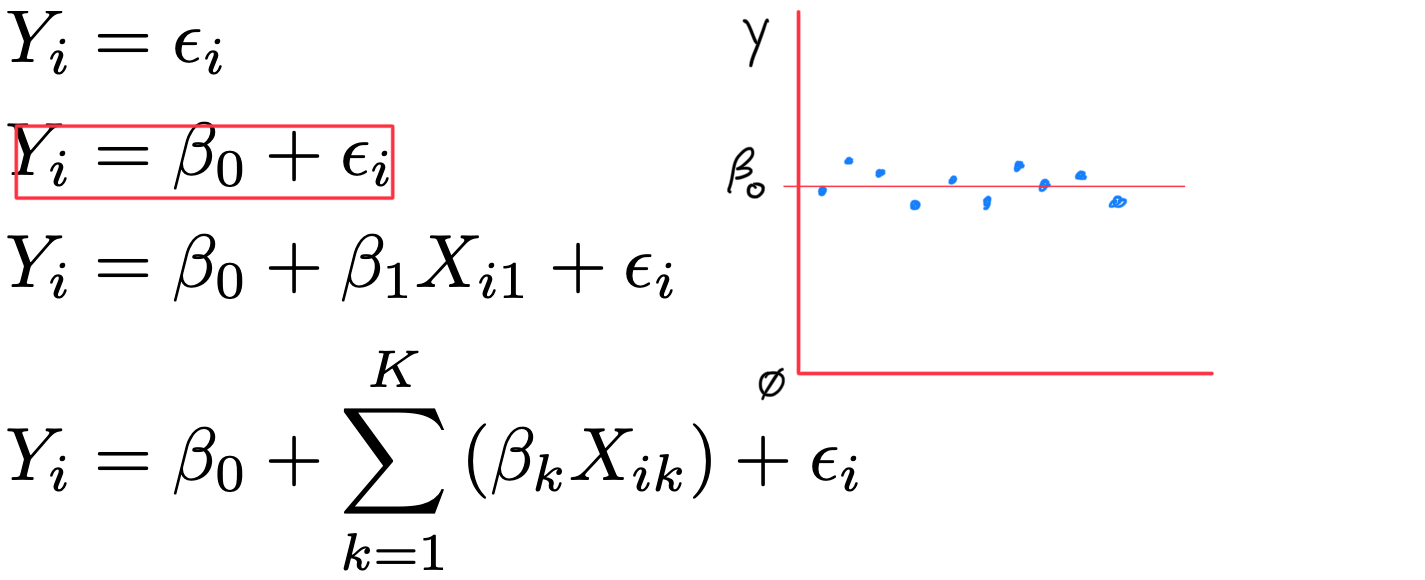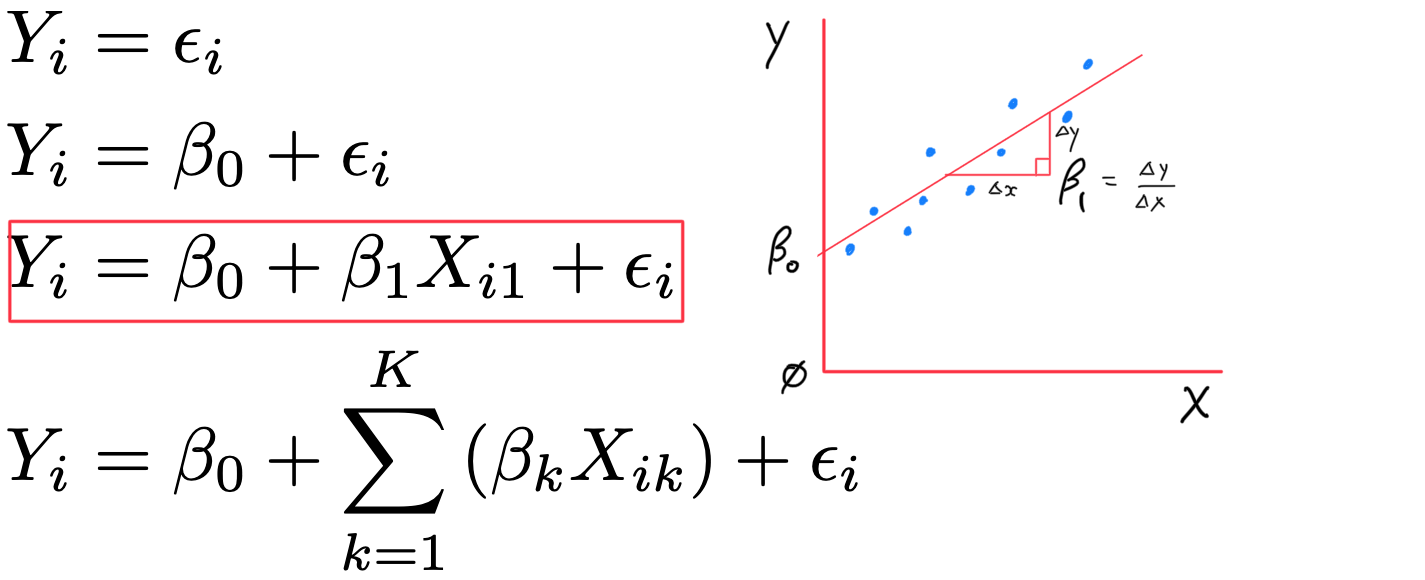g x
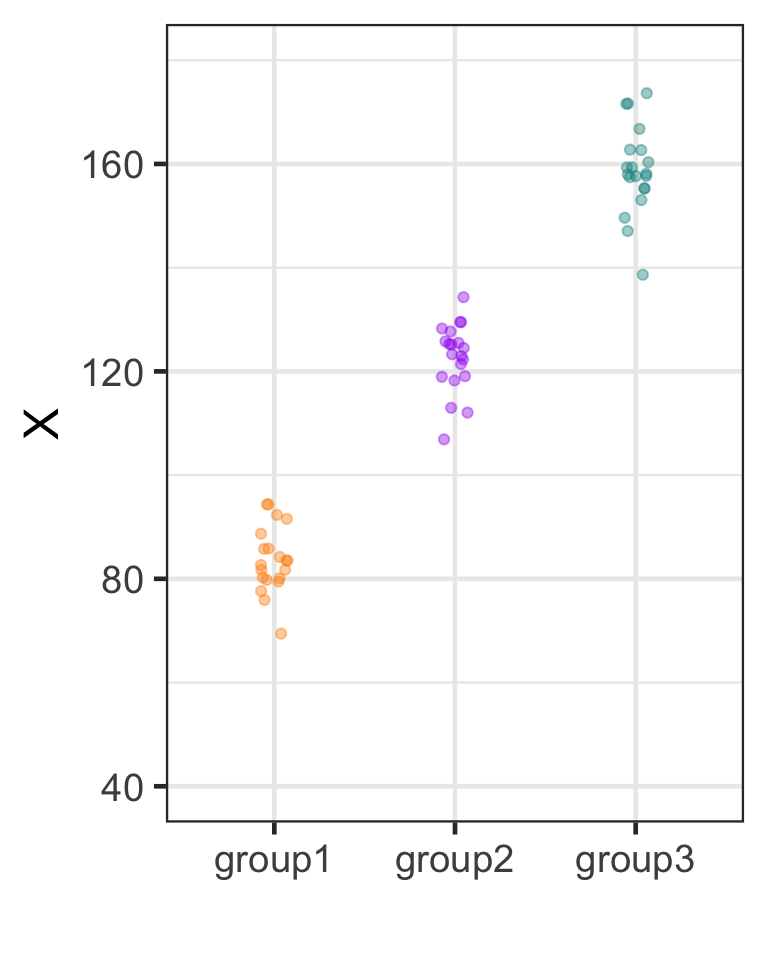
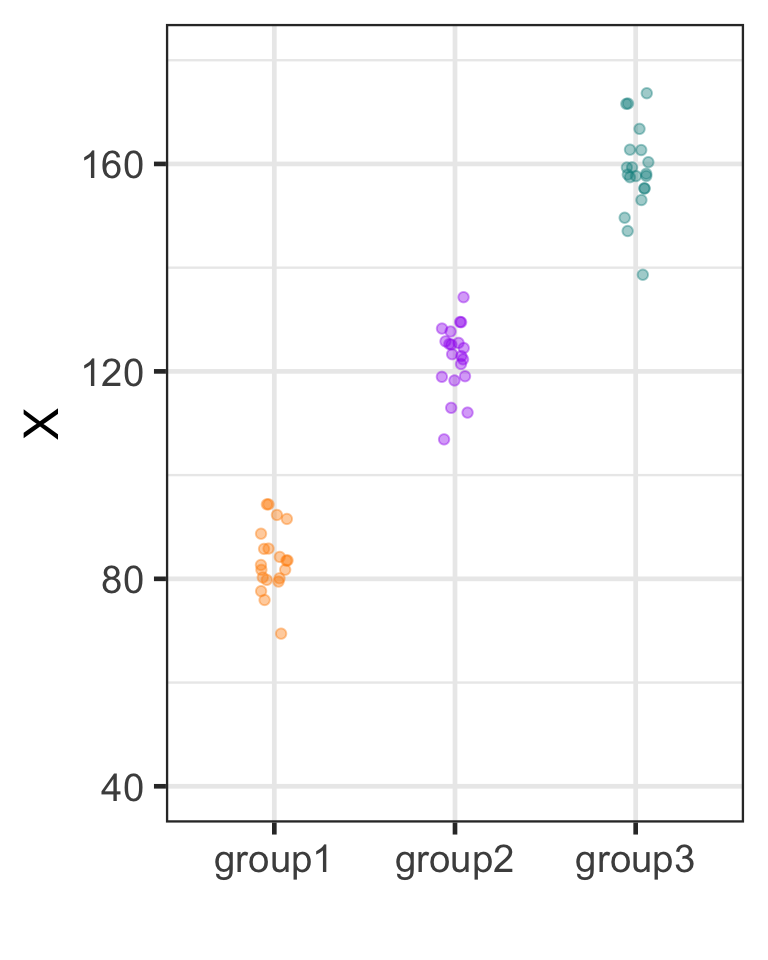
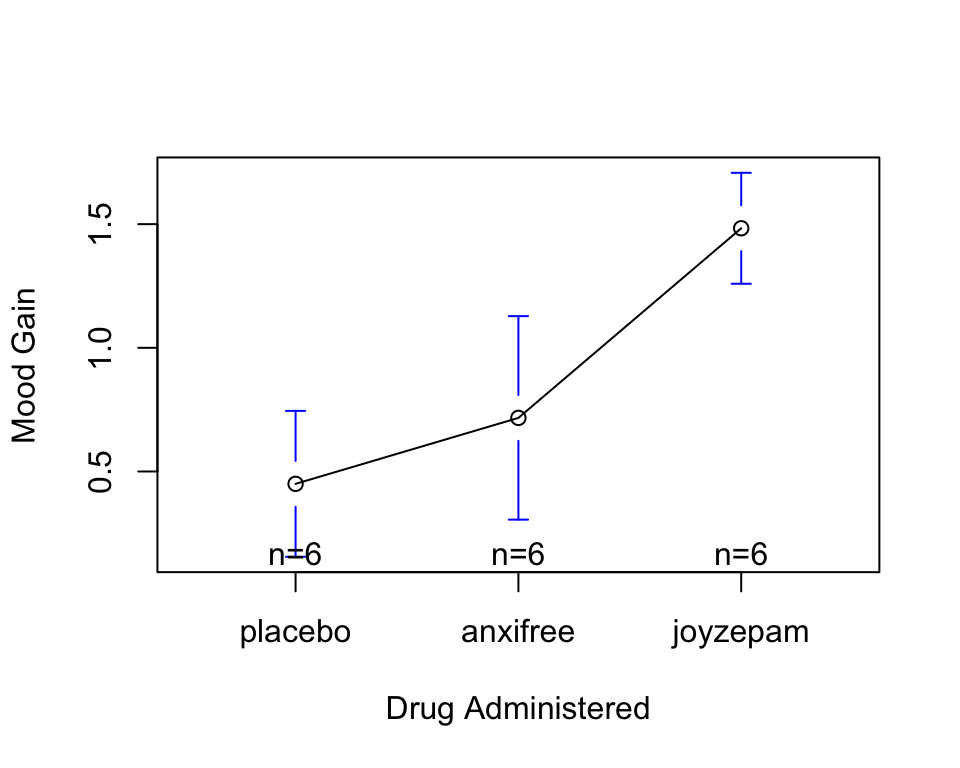
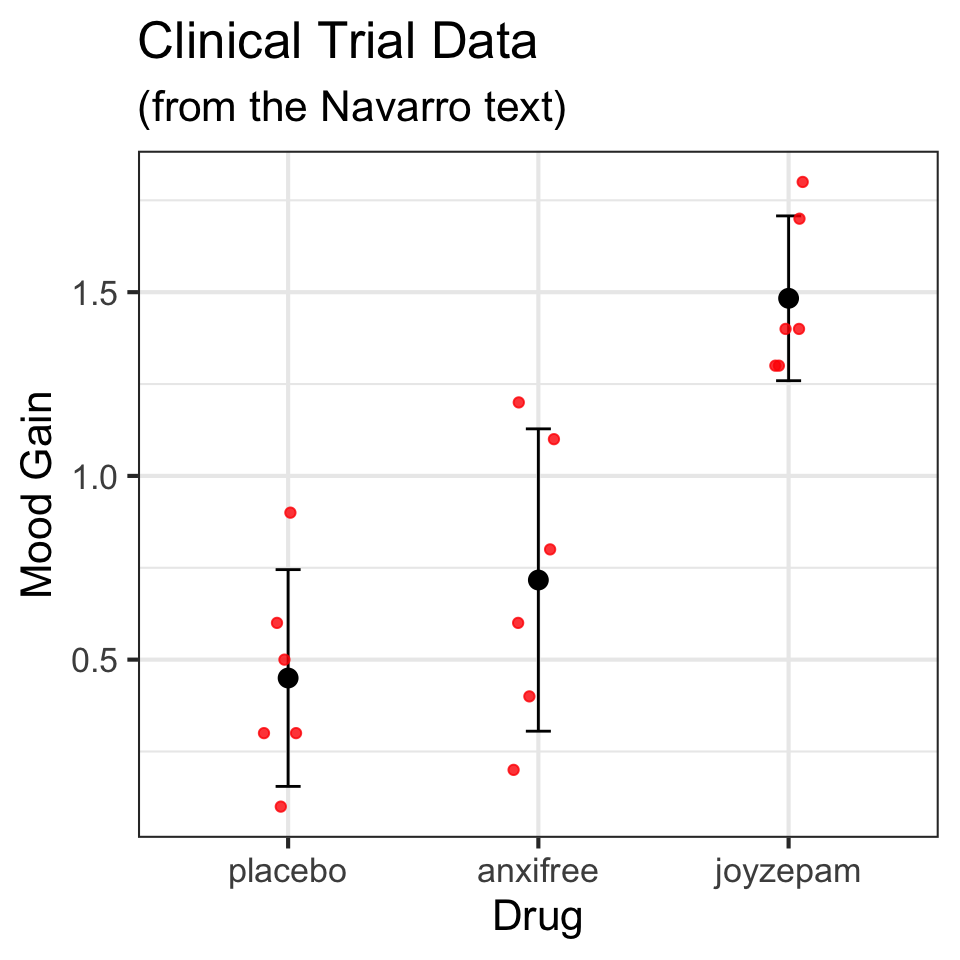
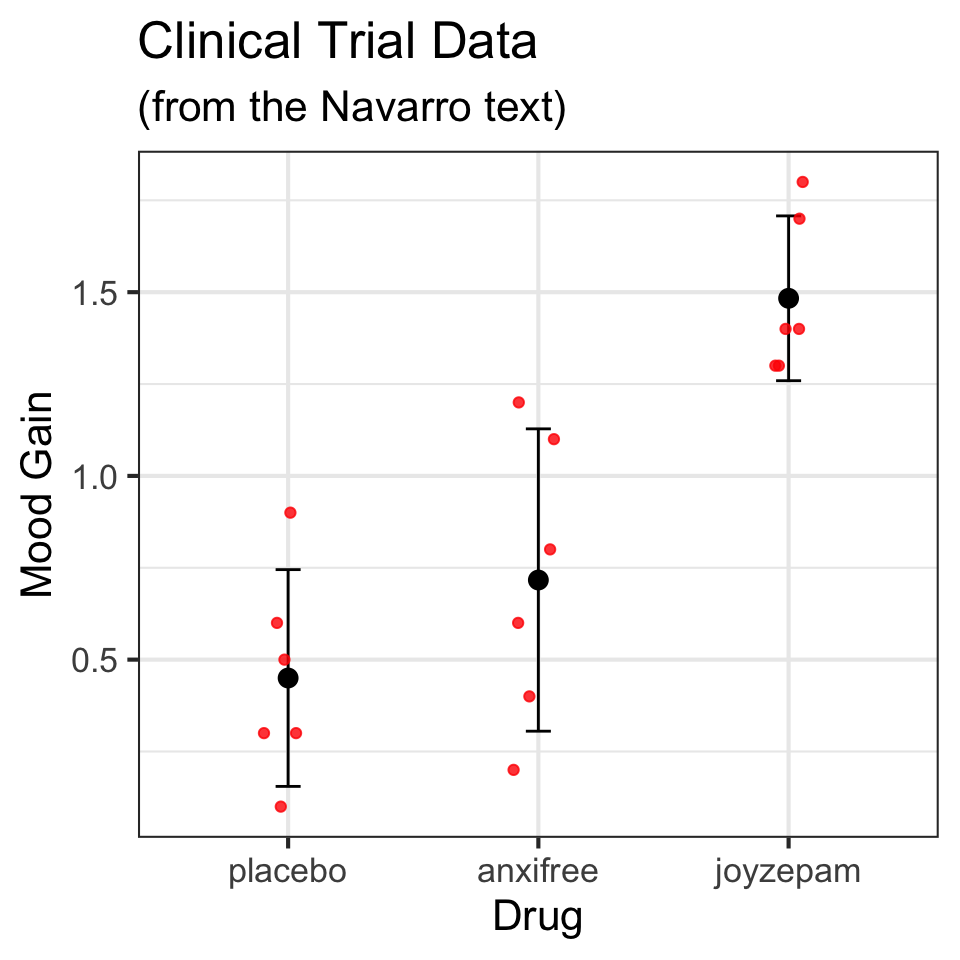
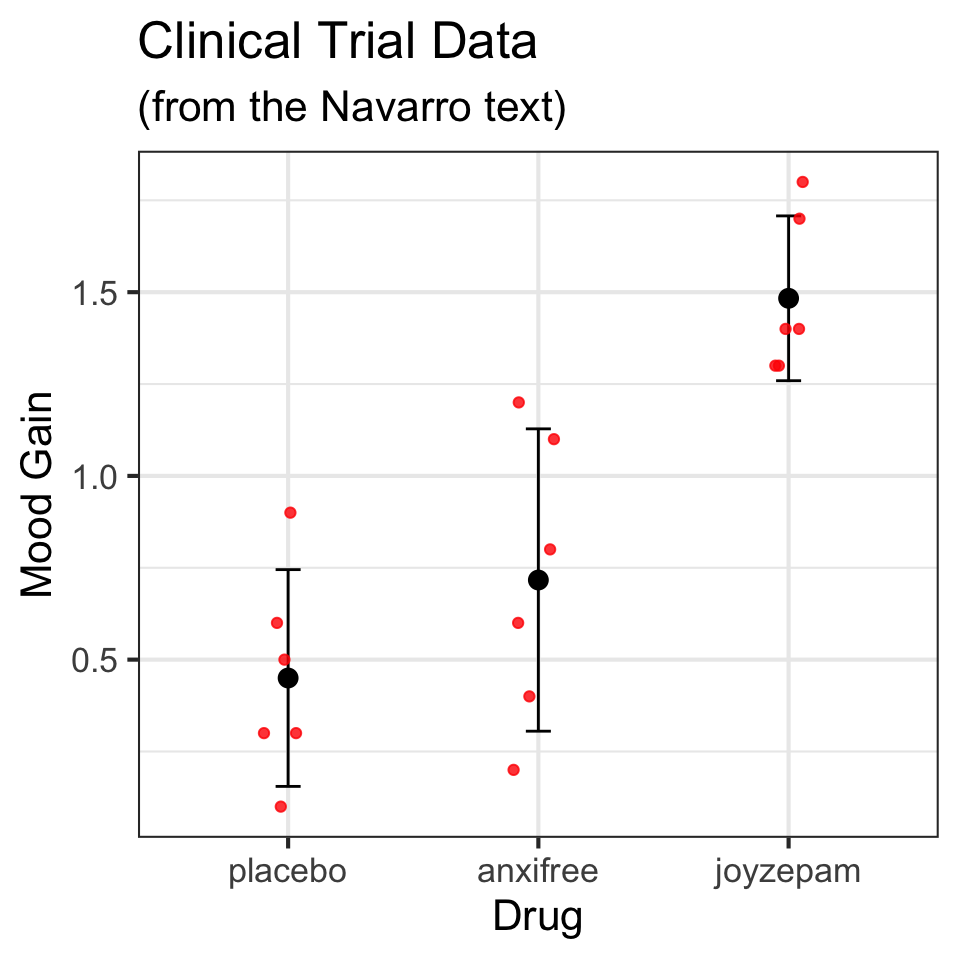
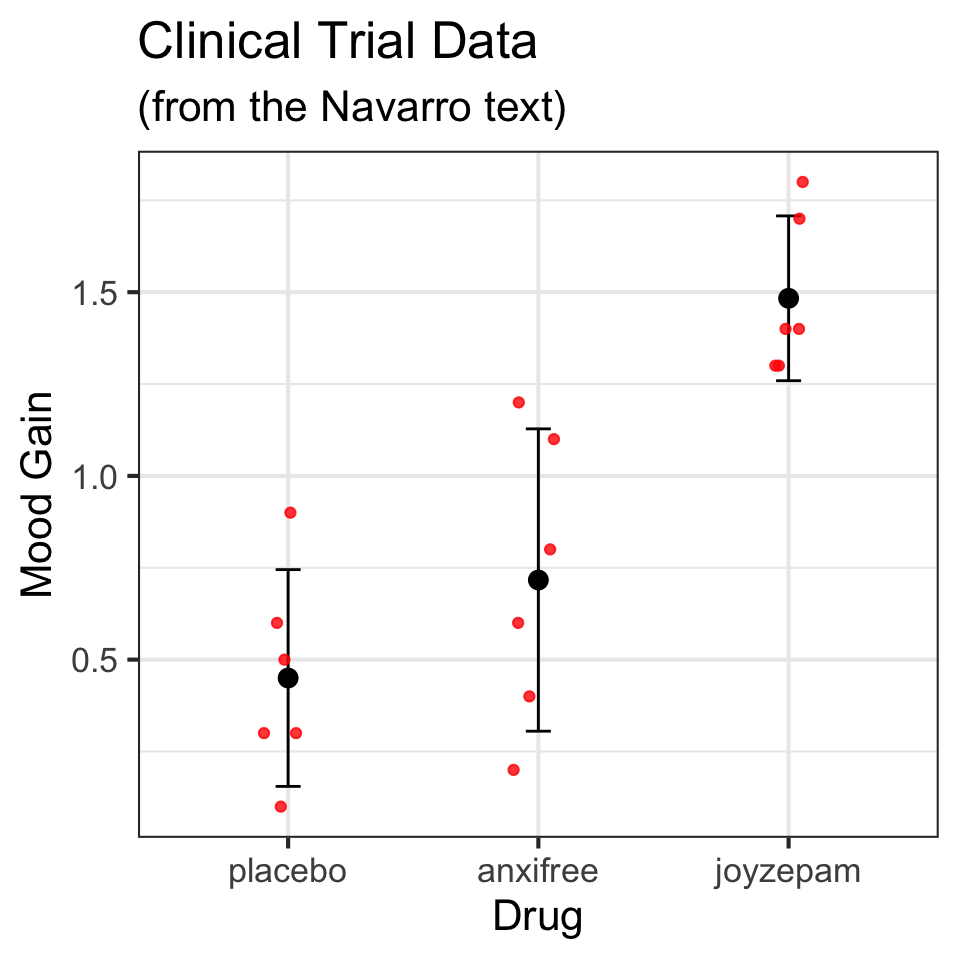
1 treatment1 95.75
2 treatment2 116.25
3 treatment3 126.25
ANOVA
ANOVA stands for ANalysis Of VAriance
ANOVA is a statistical test that compares the means of two or more groups
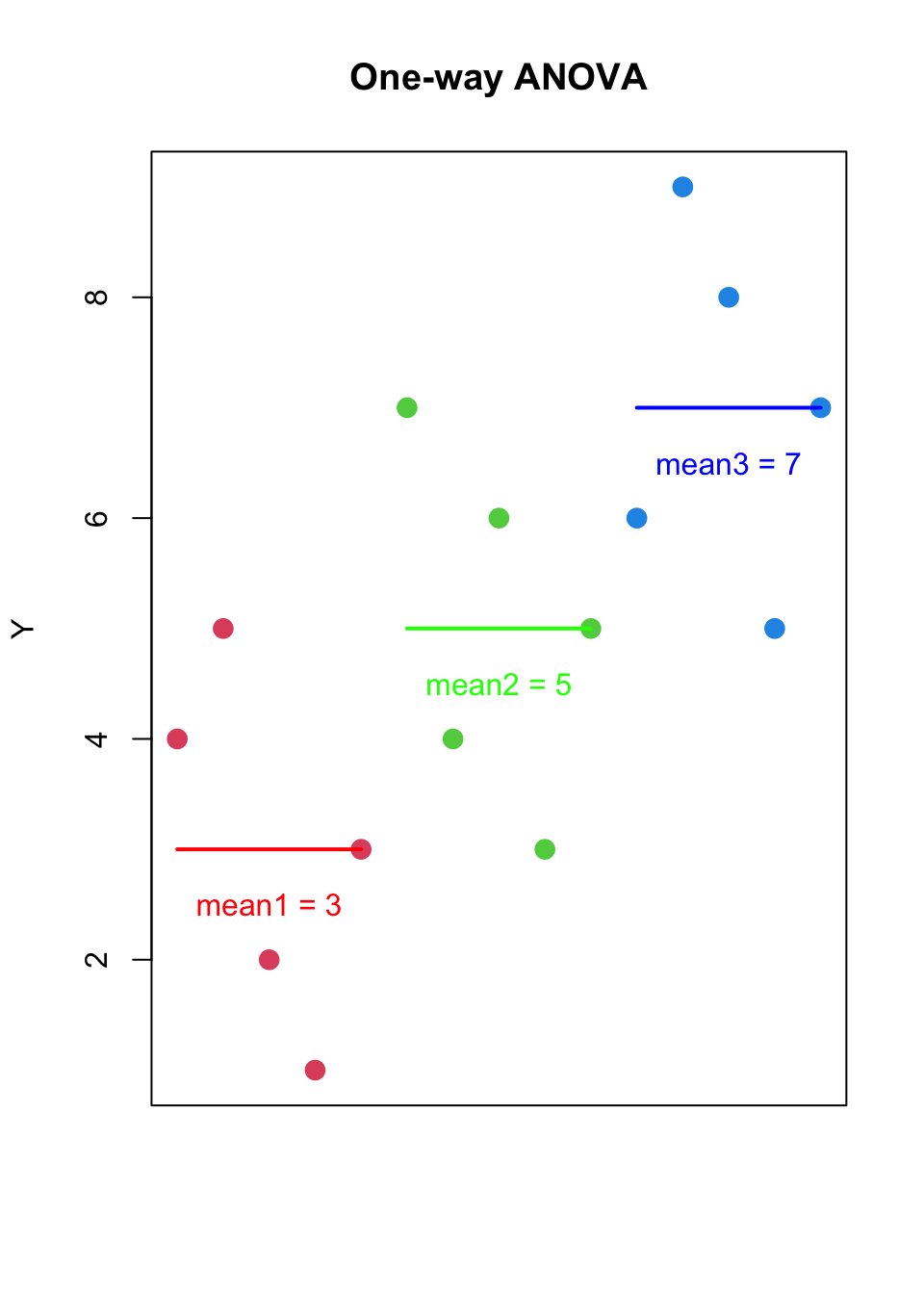
many forms of ANOVA exist, but we will start with the simplest:
one-way between-subjects ANOVA
(read Navarro, chapter 14)
one-way between-subjects ANOVA
one-way: one independent variable
later we will see two-factor ANOVA and n-factor ANOVA
between-subjects: each participant contributes an observation in only one group
later we will see within-subjects ANOVA and mixed ANOVA
Omnibus F-test
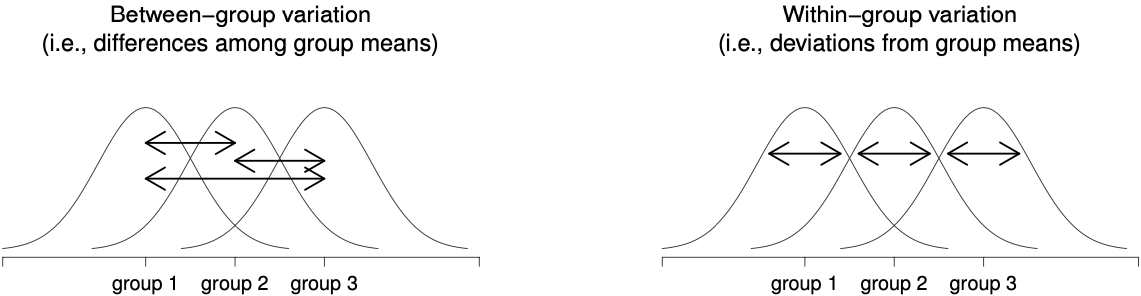
ANOVA computes an “omnibus” F-statistic, which is a ratio of two variances
(omnibus means “overall”)
the numerator is the between-groups variance
the denominator is the within-groups variance
Omnibus F-statistic is a metric of the “overall” question:
“are the means of the groups the same? (or not the same)?”
Omnibus F-test
Omnibus F-test
F = \frac{\mathrm{BetweenVariance}}{\mathrm{WithinVariance}}
what is F going to be?
F-ratio far above 1.0: between-groups variance is larger than within-groups variance
Omnibus F-test
F = \frac{\mathrm{BetweenVariance}}{\mathrm{WithinVariance}}
what is F going to be?
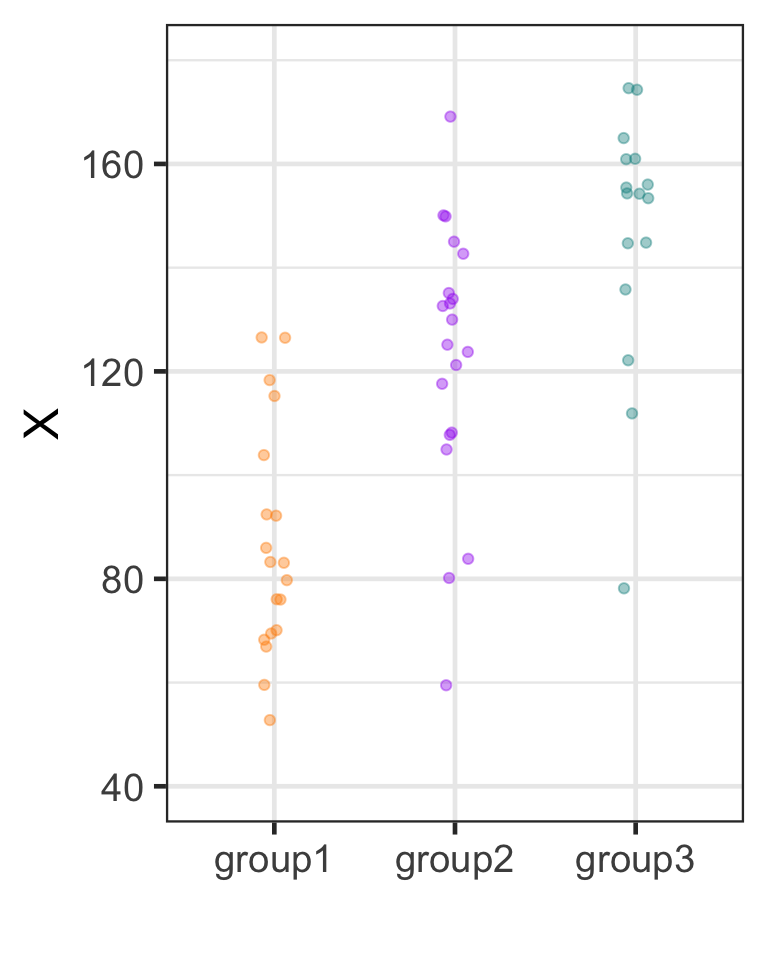
F-ratio below 1.0: between-groups variance is smaller than within-groups variance
Omnibus F-test
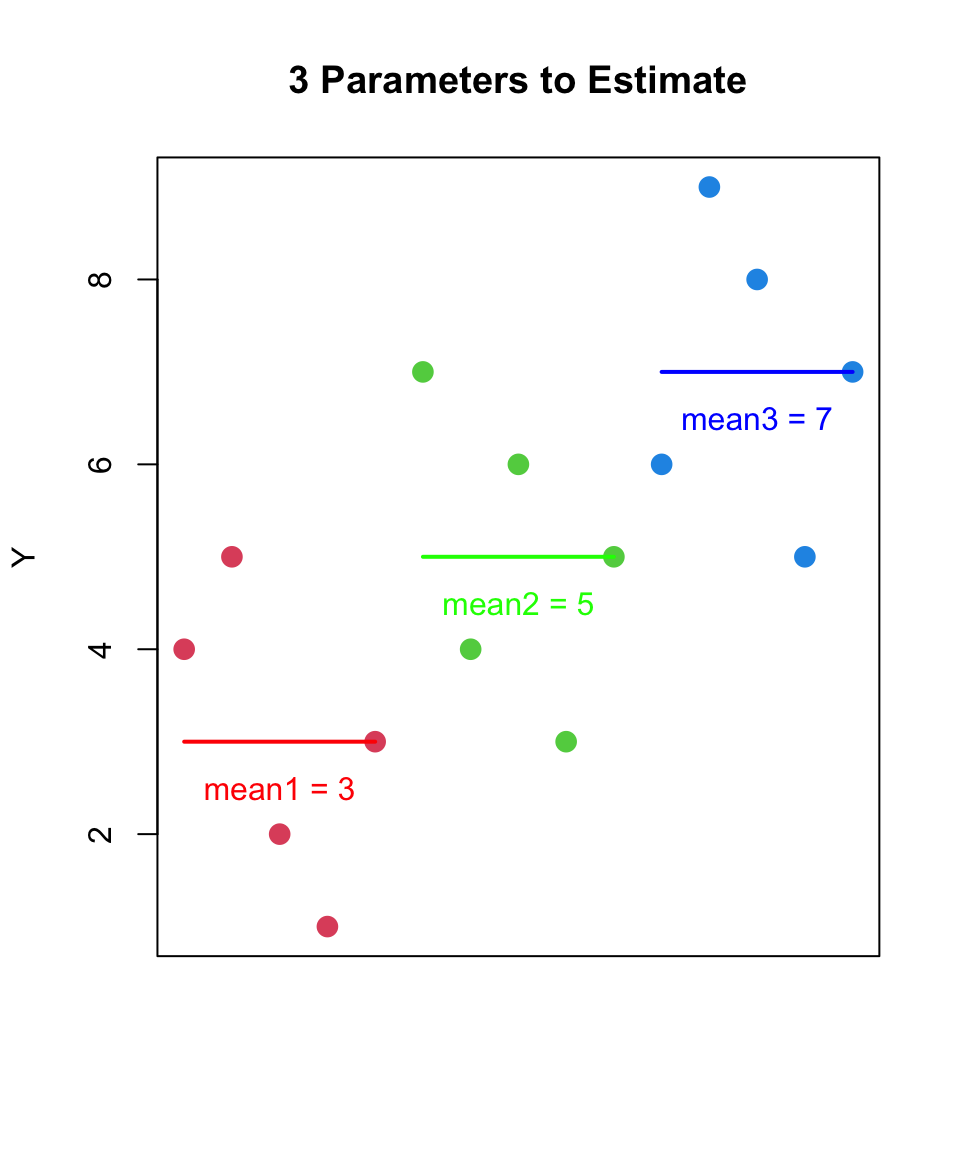
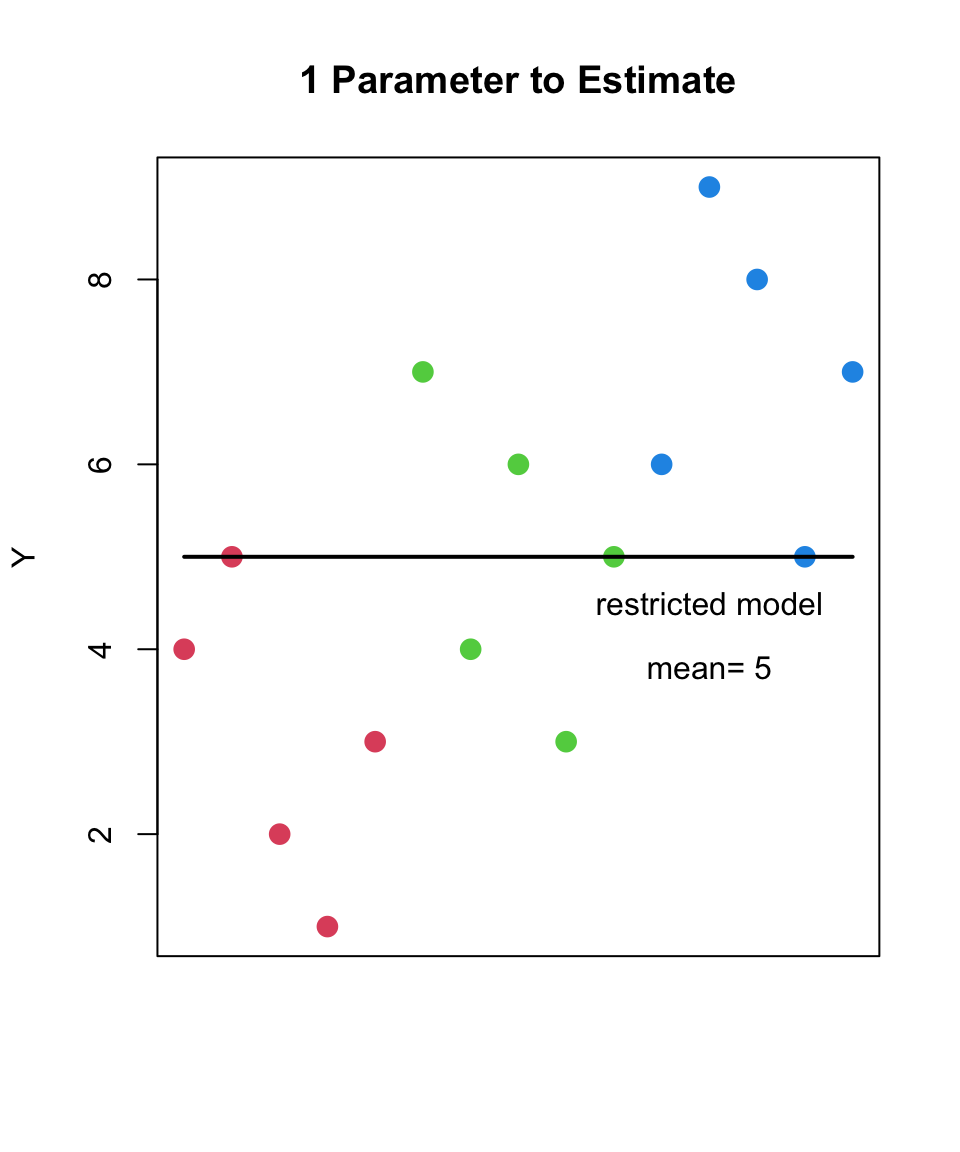
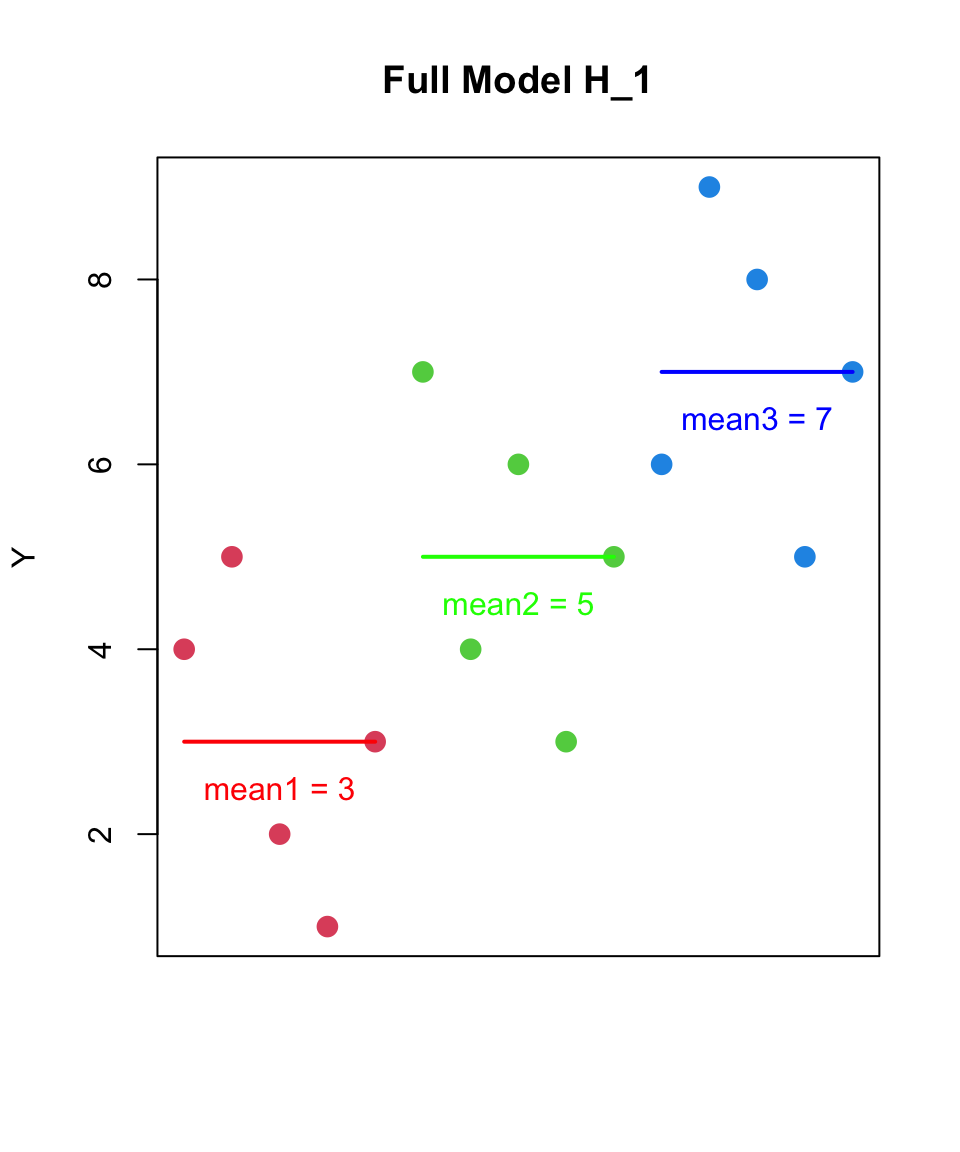
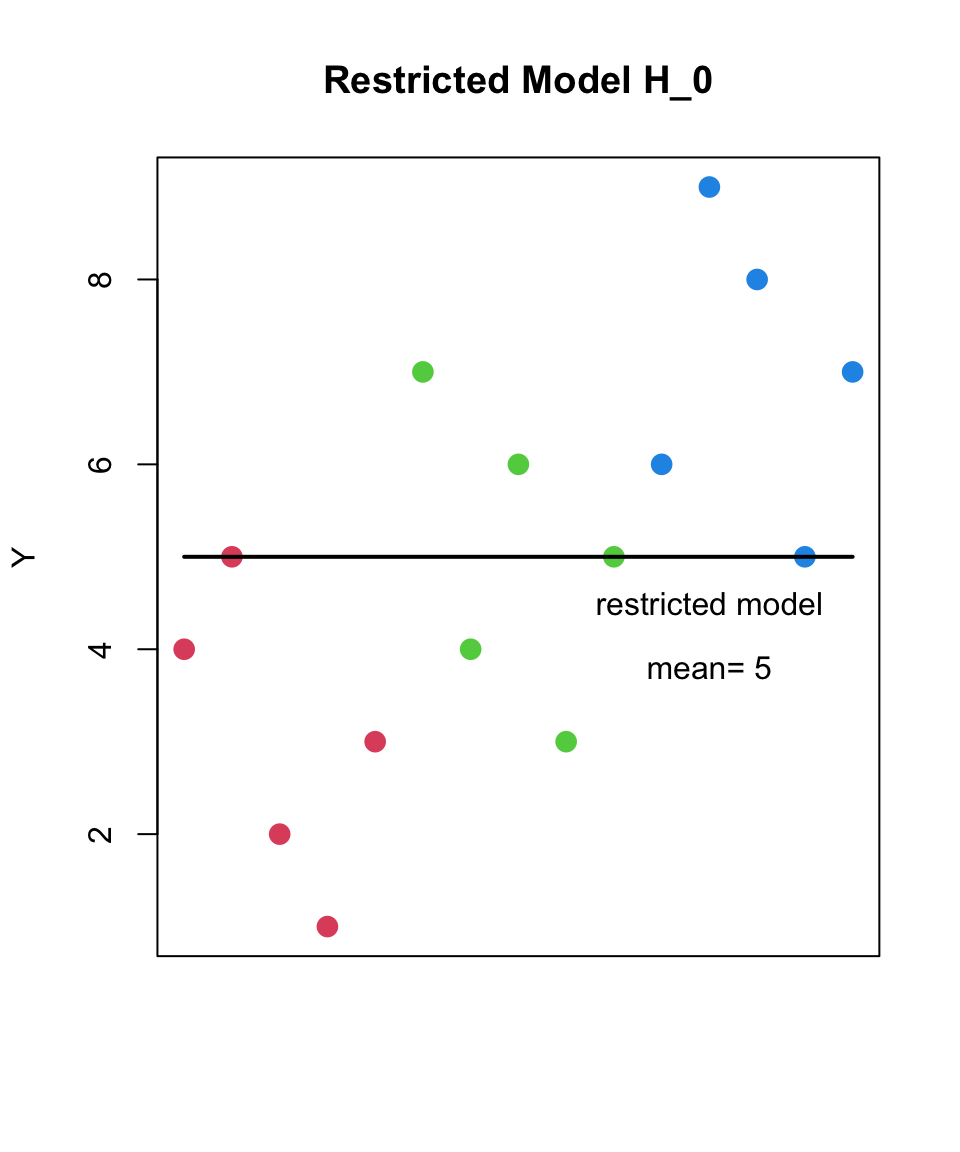
the null hypothesis is that the means of all groups are equal
H_{0}: each group was sampled from the same population
H_{1}: at least one group was sampled from a different population (with a different population mean)
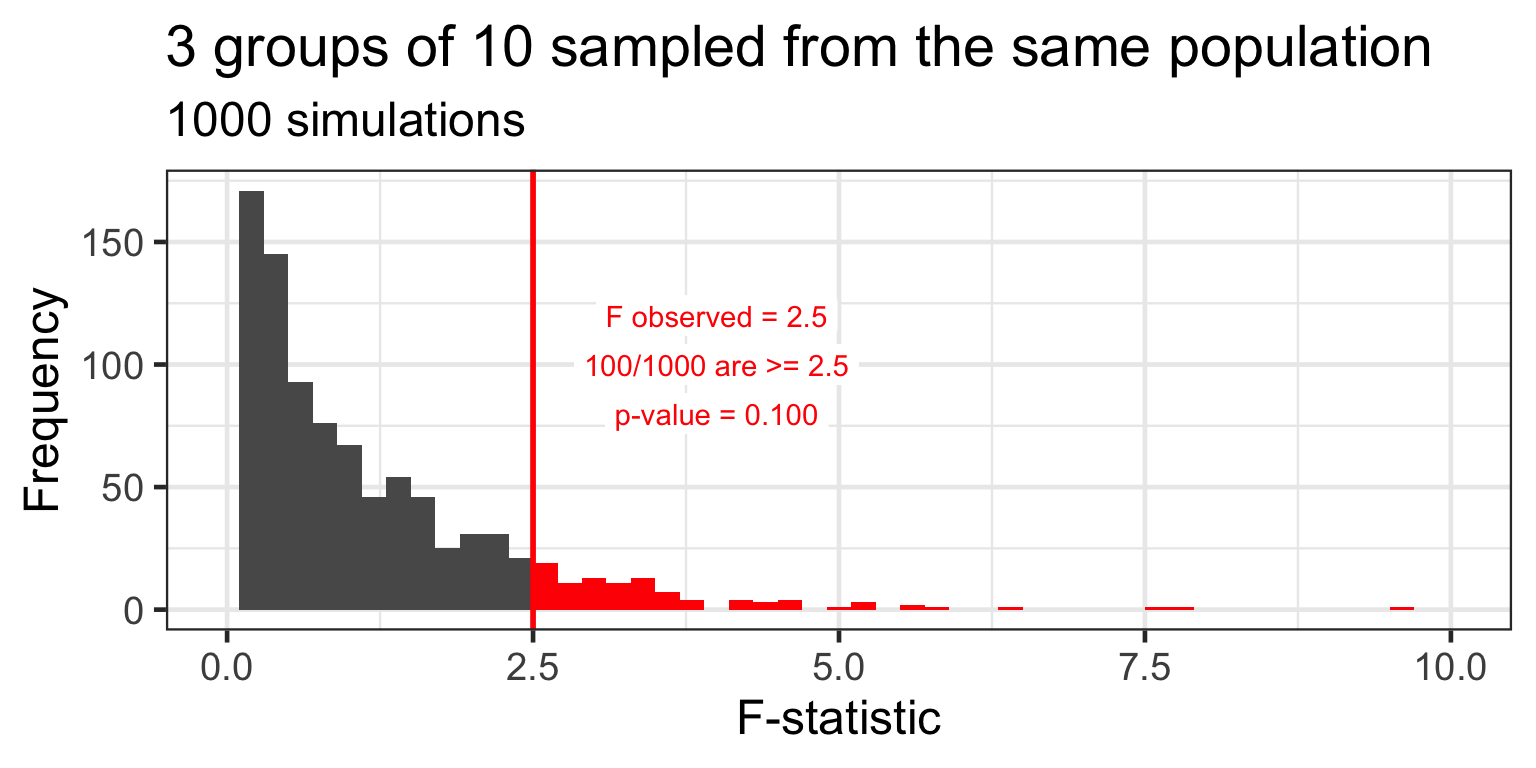
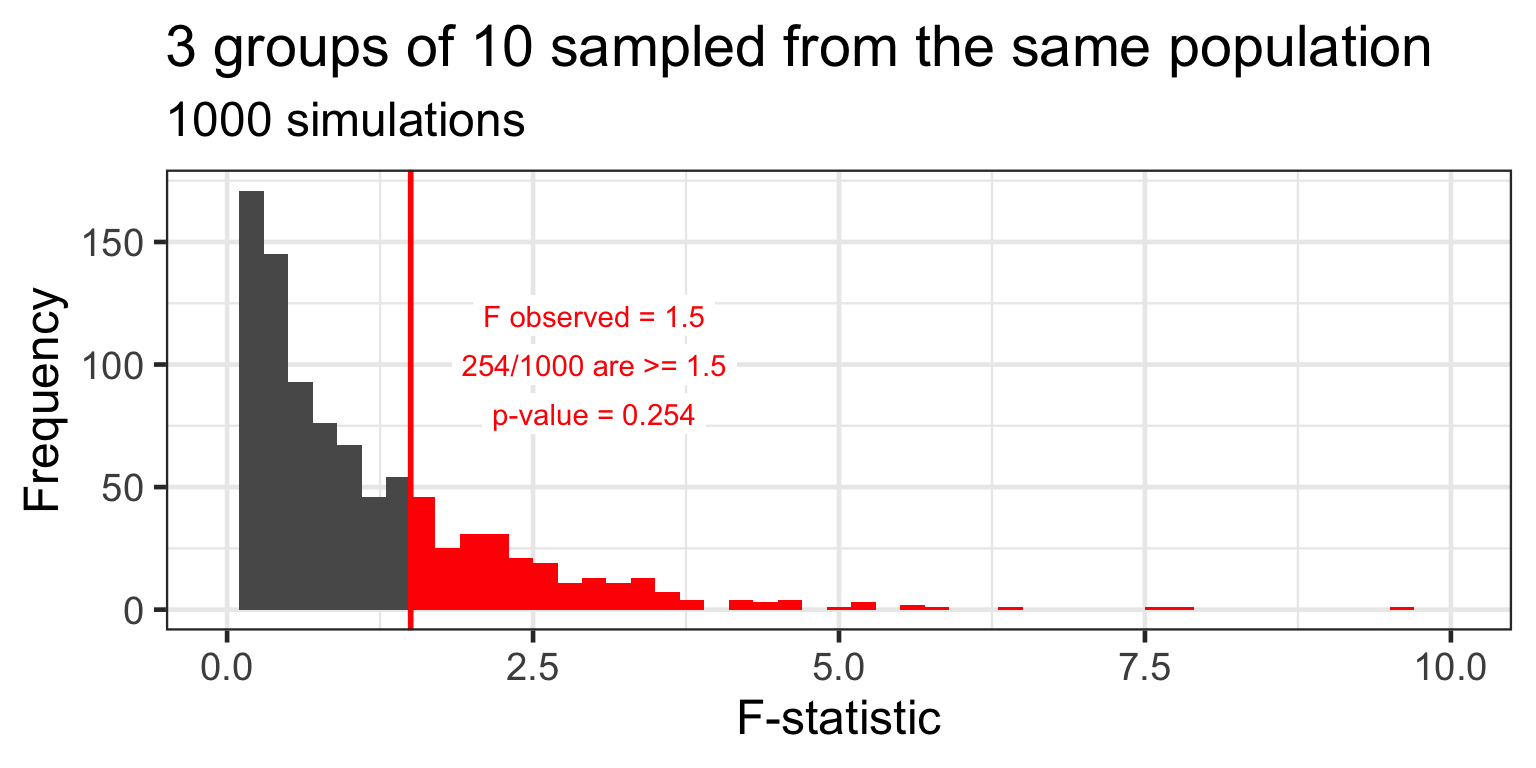
the p-value for the omnibus F-test is the probability of observing an F-statistic as large as the one computed, assuming that the null hypothesis is true
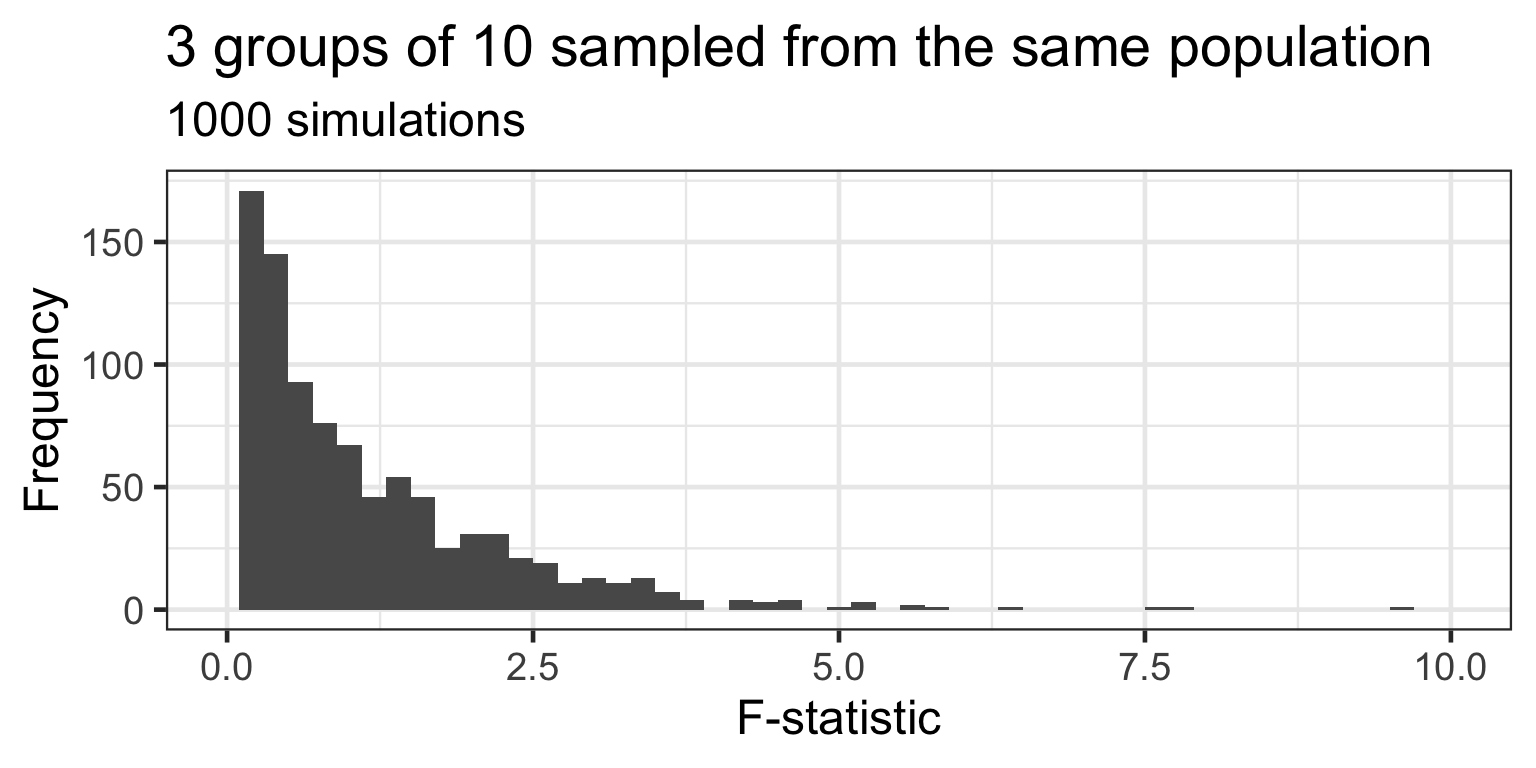
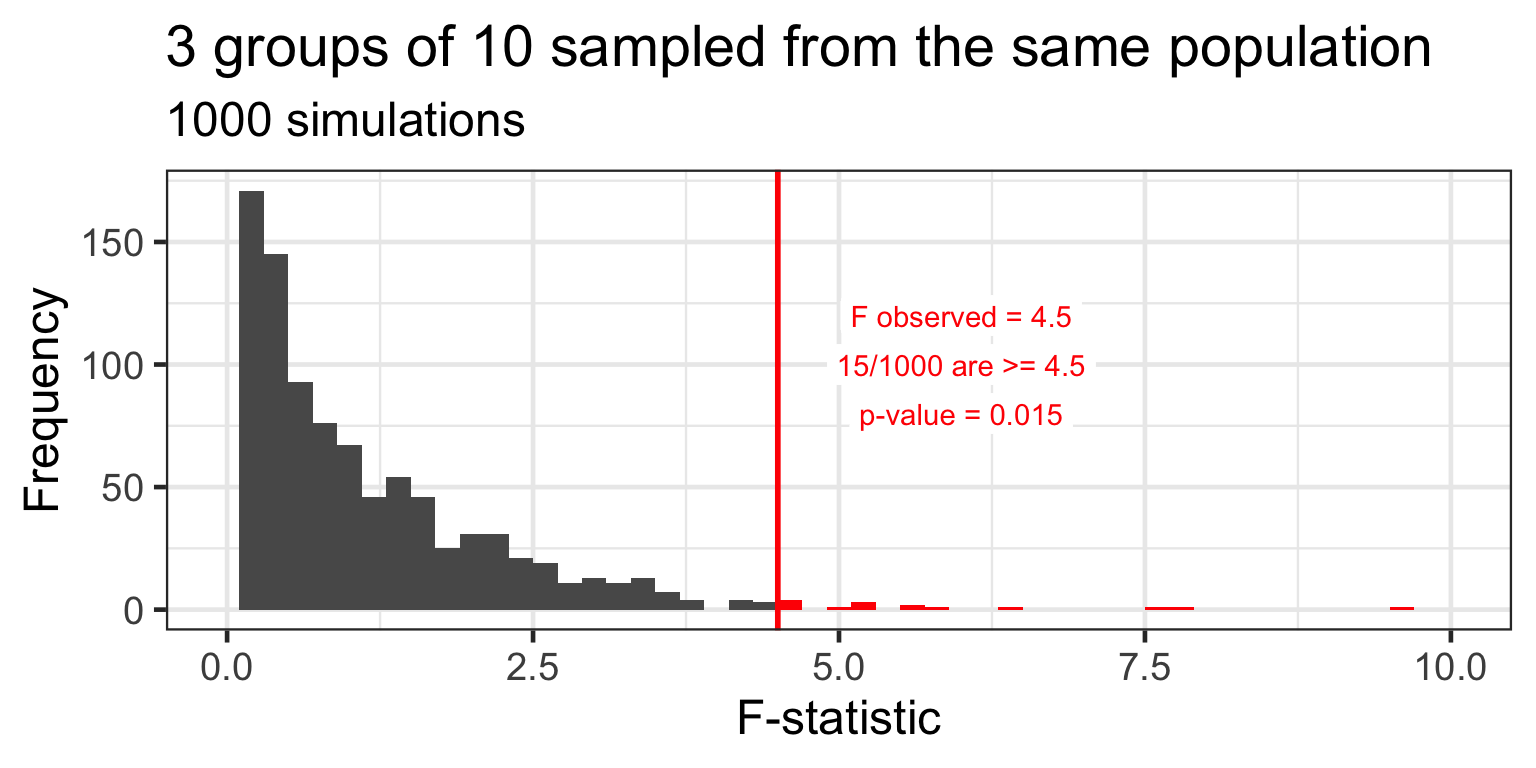
Distribution of F under H_{0}
under the null hypothesis, there are no differences between groups in the population
but random sampling results in differences between sample groups
the F-statistic is an overall (omnibus) measure of the differences between all groups
under the null hypothesis we expect the F-statistic to be close to 1.0 most of the time
but due to random sampling, under the null hypothesis, sometimes it will be larger
the p-value tells us how likely is it to observe a given F-statistic under H_{0}
Distribution of F under H_{0}
Distribution of F under H_{0}
Distribution of F under H_{0}
Distribution of F under H_{0}
Omnibus F-test
following a significant omnibus F-test, we can perform follow-up tests to determine which groups differ from each other
not this week—we will cover follow-up tests next week
If the omnibus F-test is not significant, we should stop
Omnibus F-test protects us from making more Type I errors than we want
more about this next week
ANOVA Table/Formulas
\mathrm{SS_{b}} = sum of squares between
each group mean minus the grand mean of all groups
\mathrm{SS_{w}} = sum of squares within
each observation minus the group mean to which it belongs
ANOVA Table/Formulas
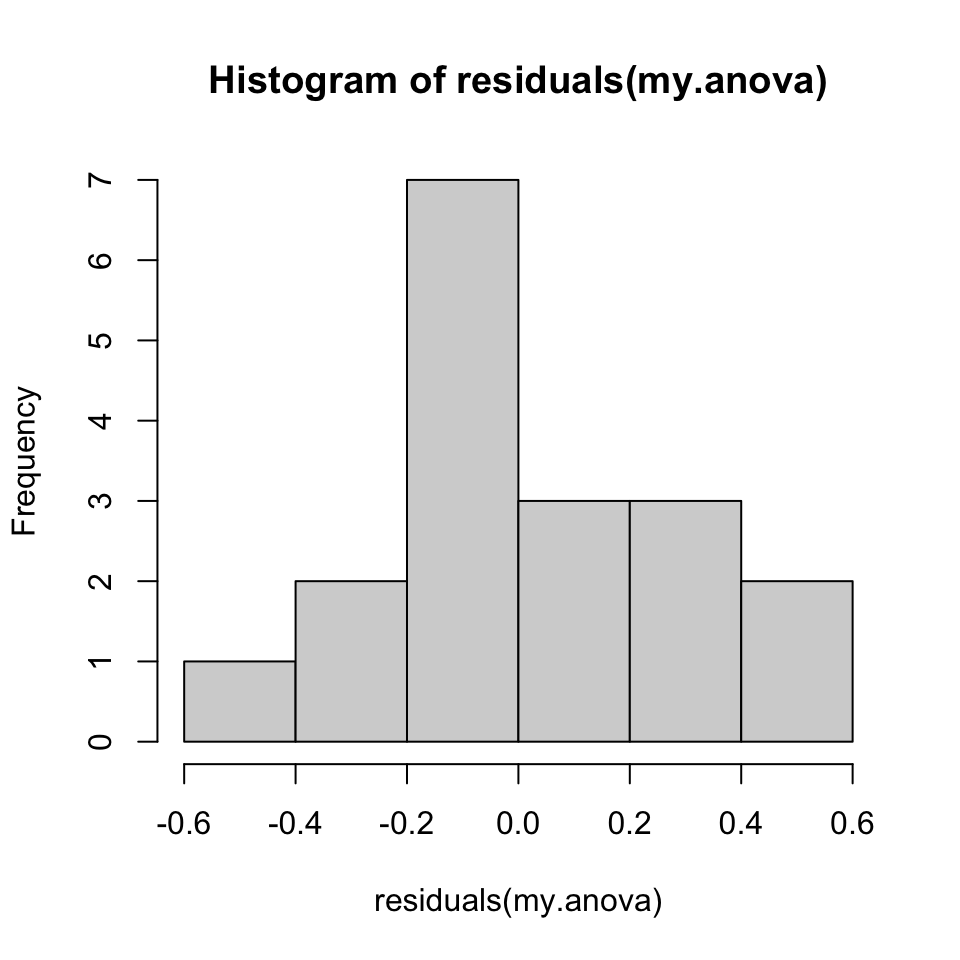
read Navarro, chapter 14, for a worked example, going from the raw data to the ANOVA table