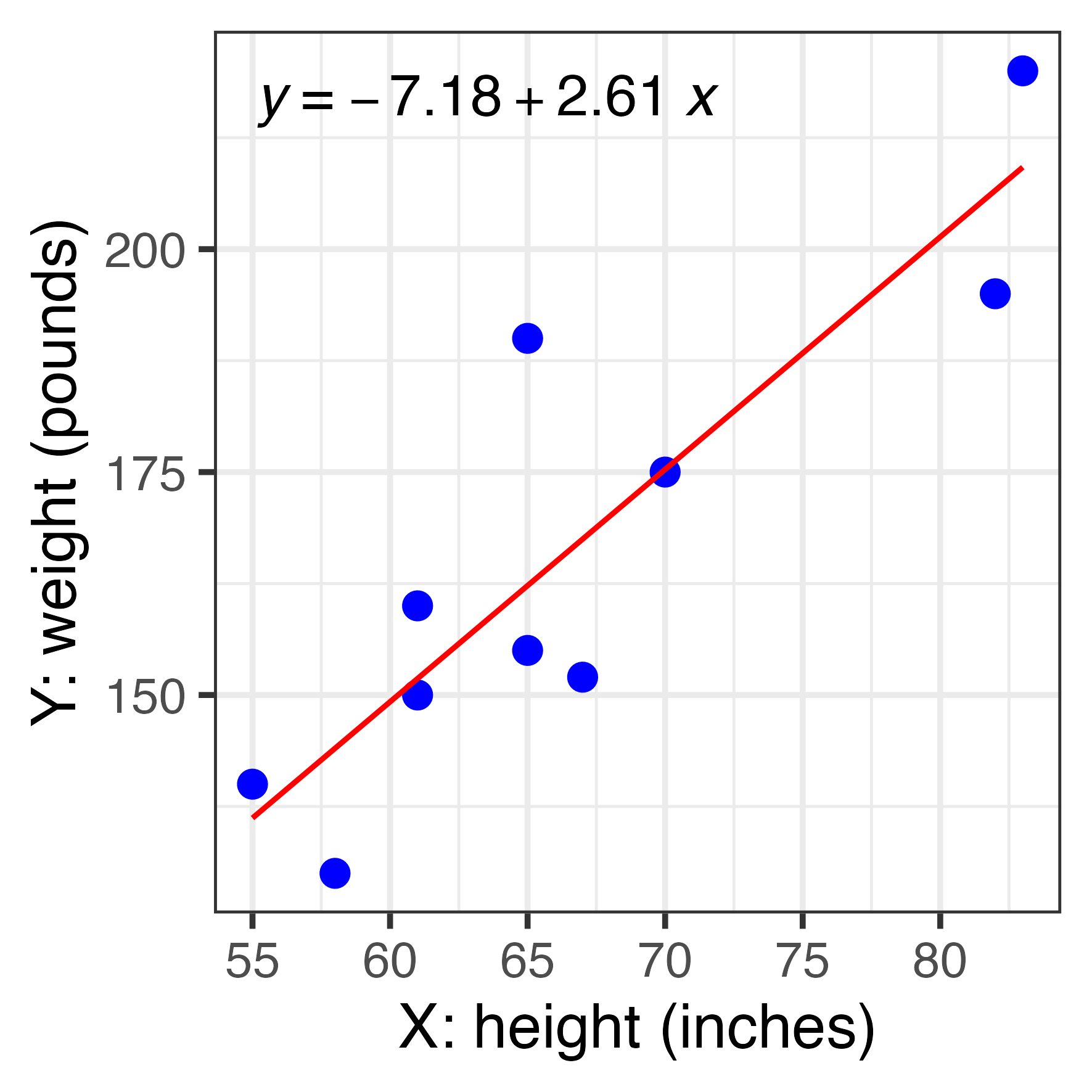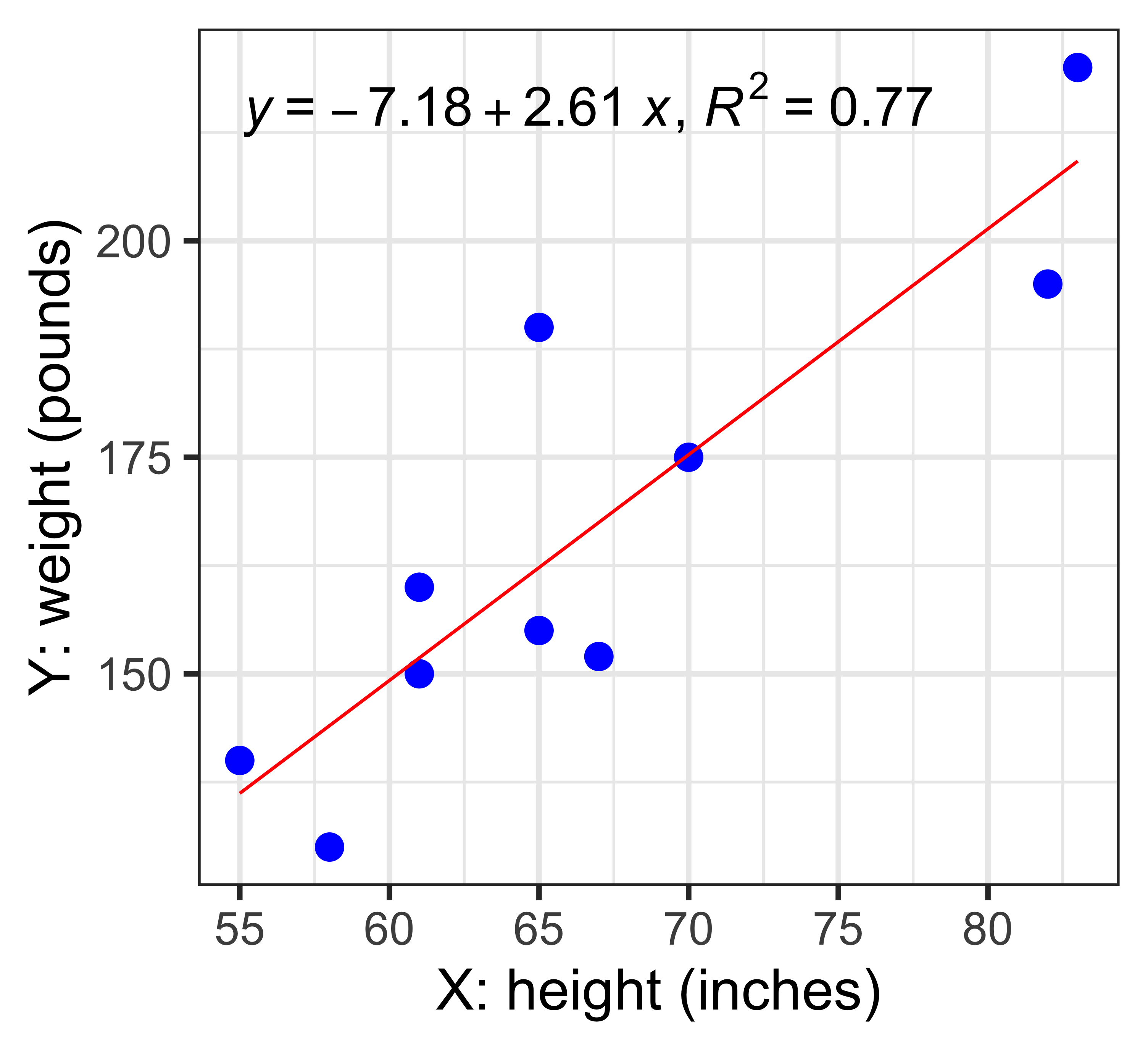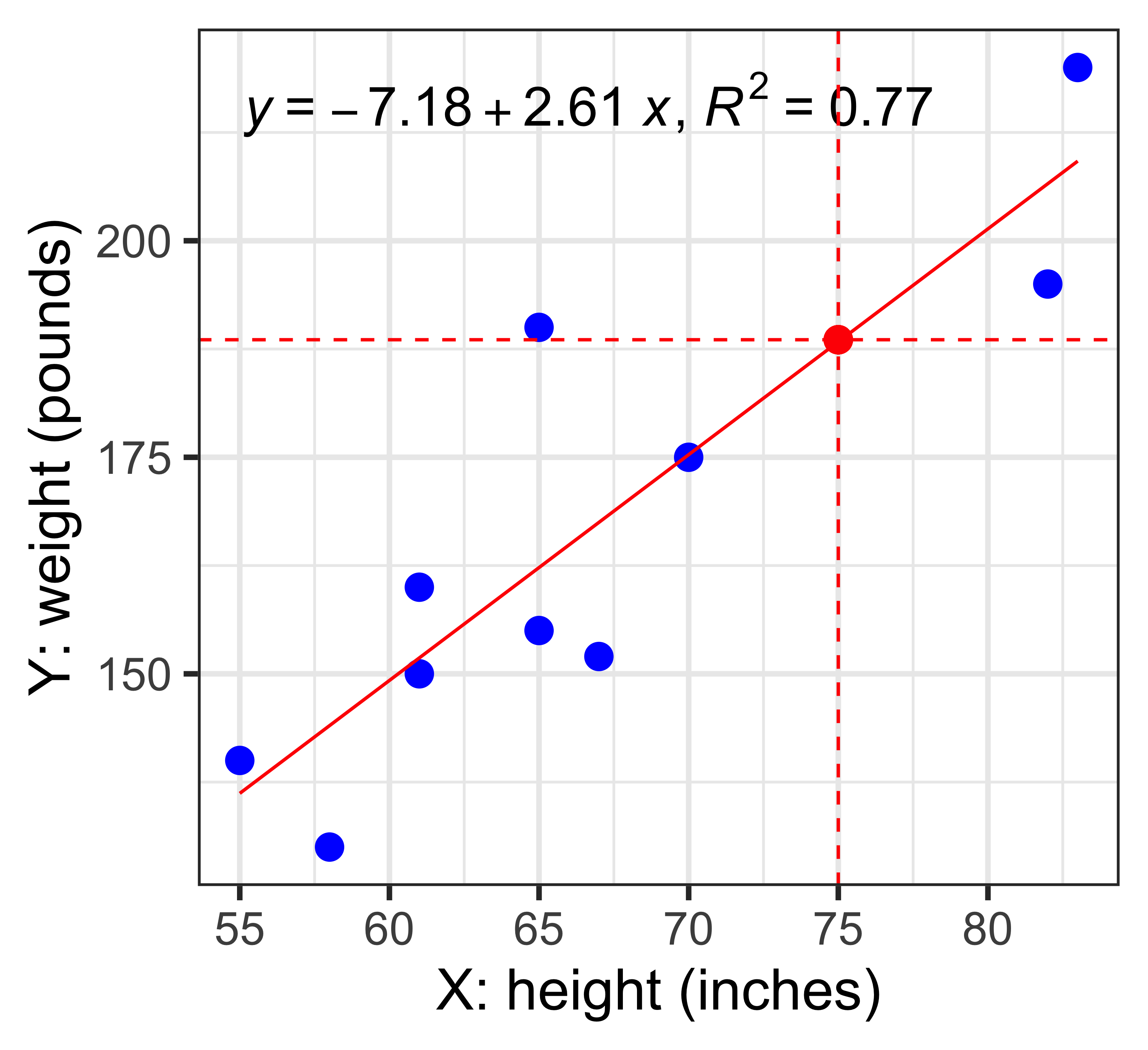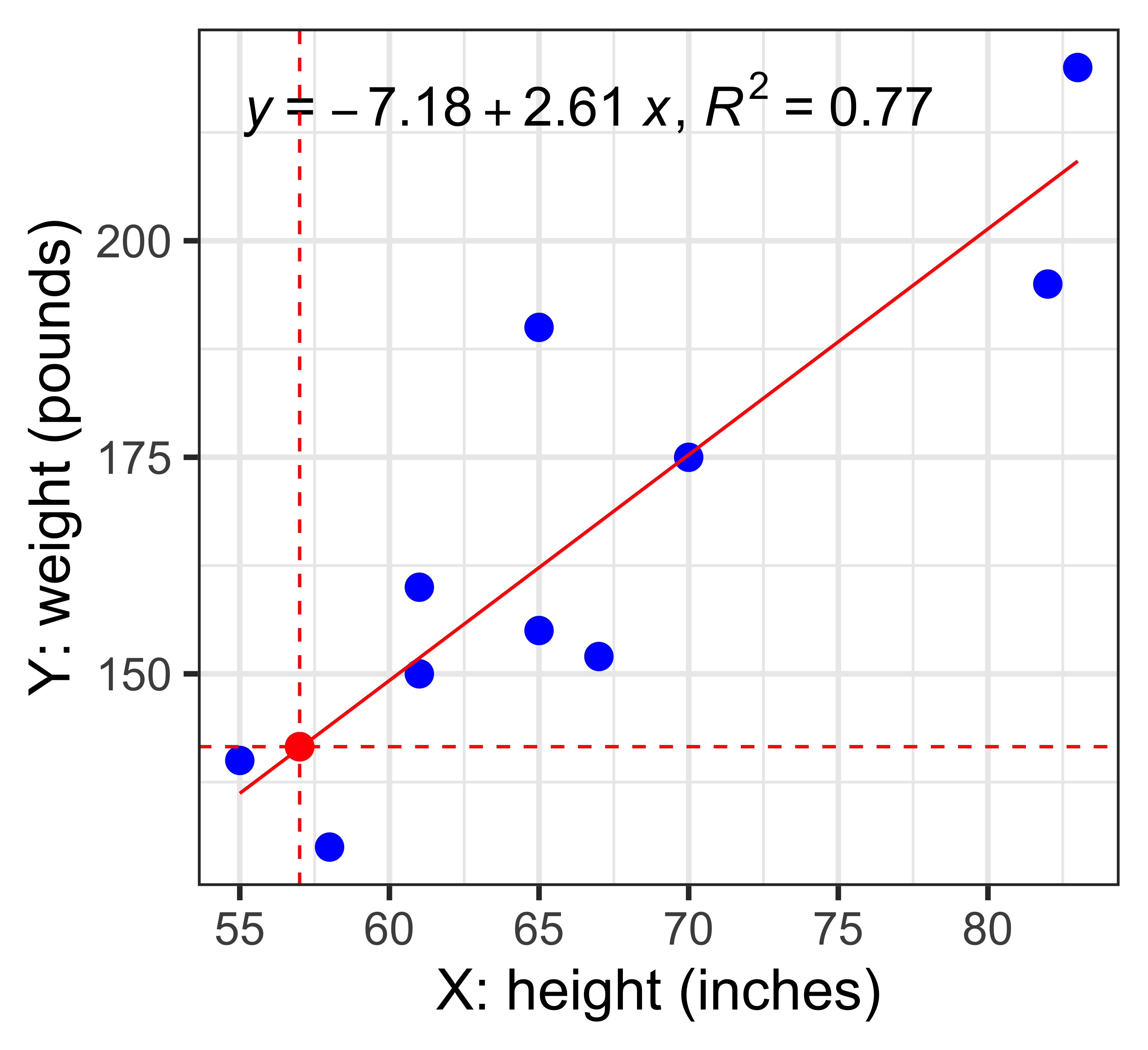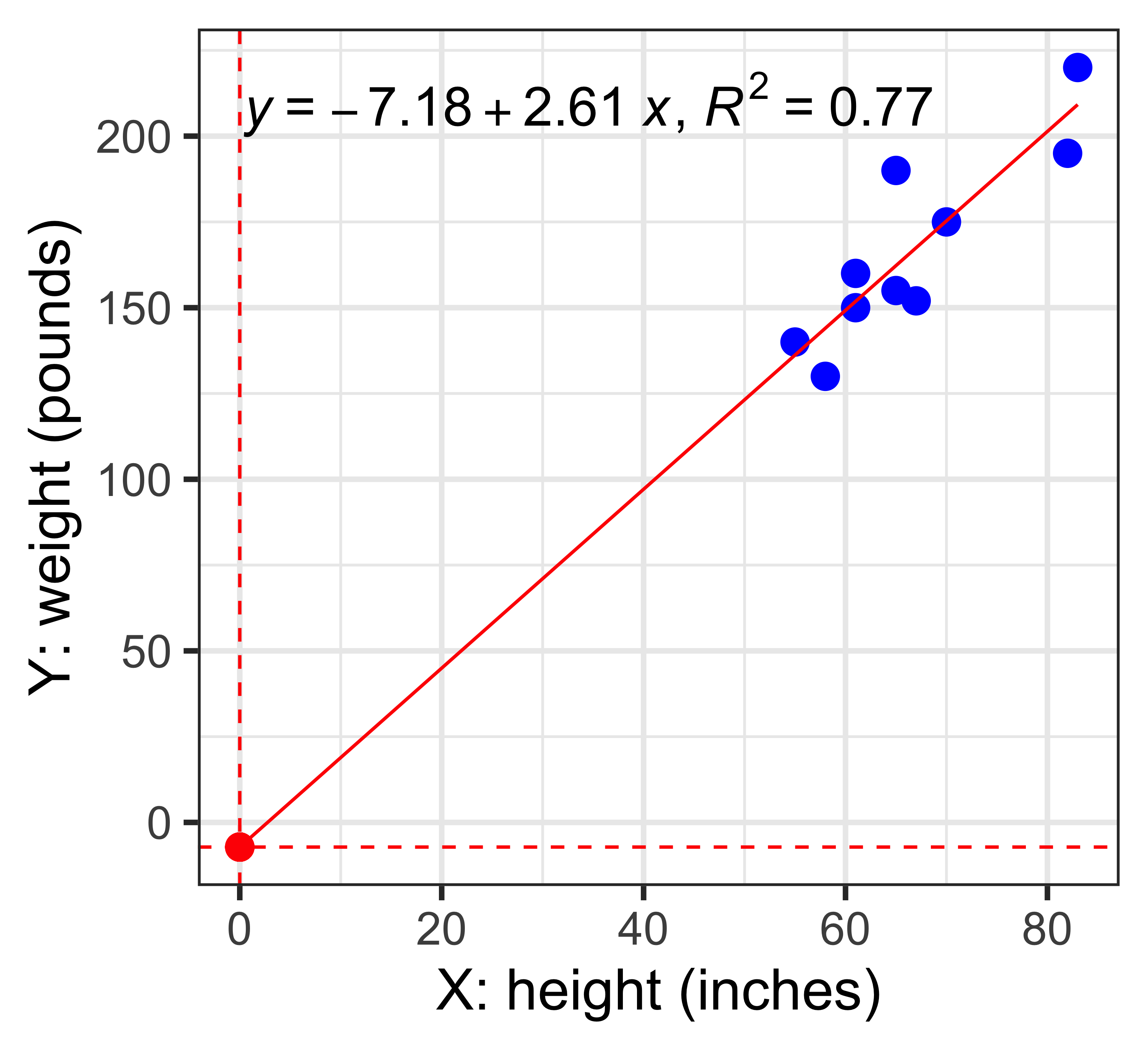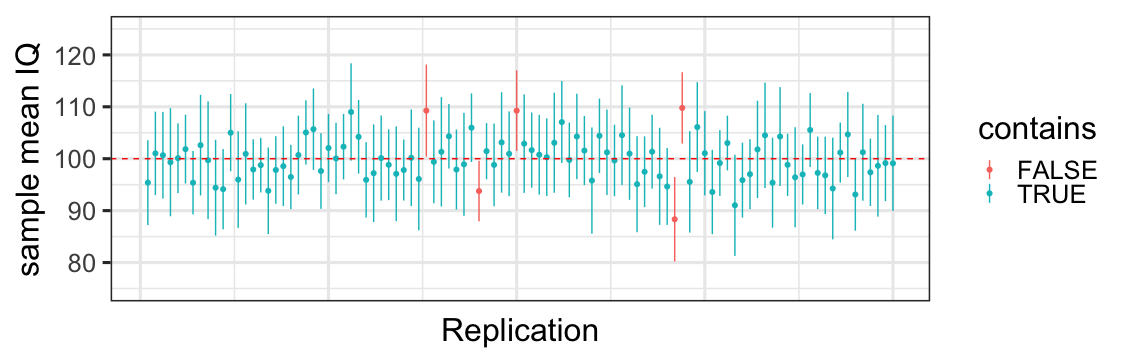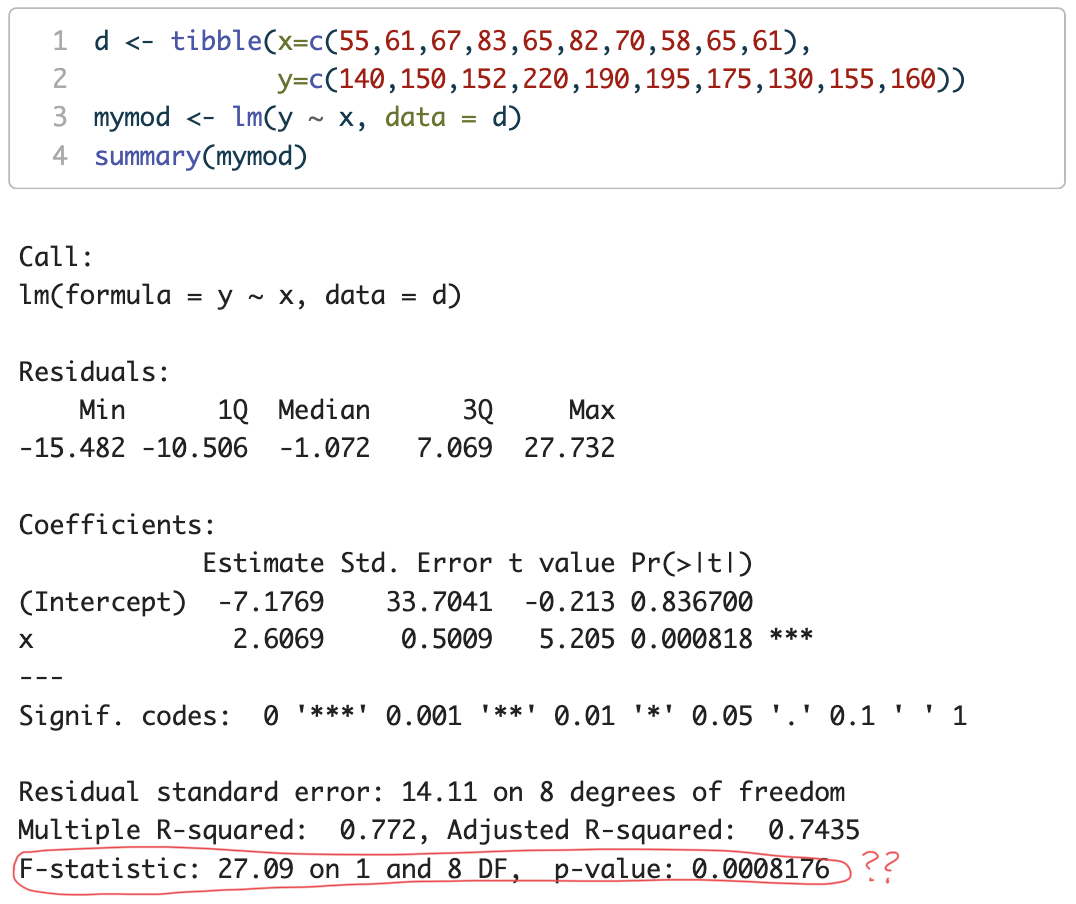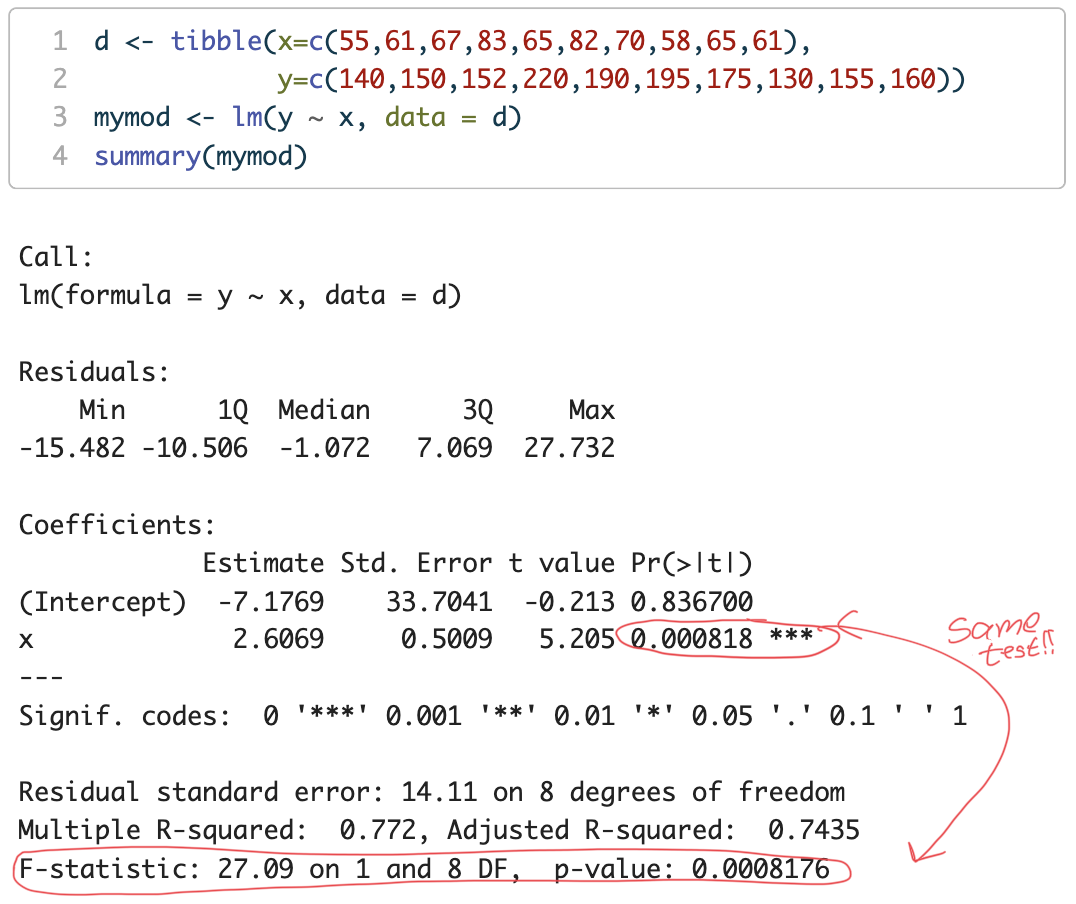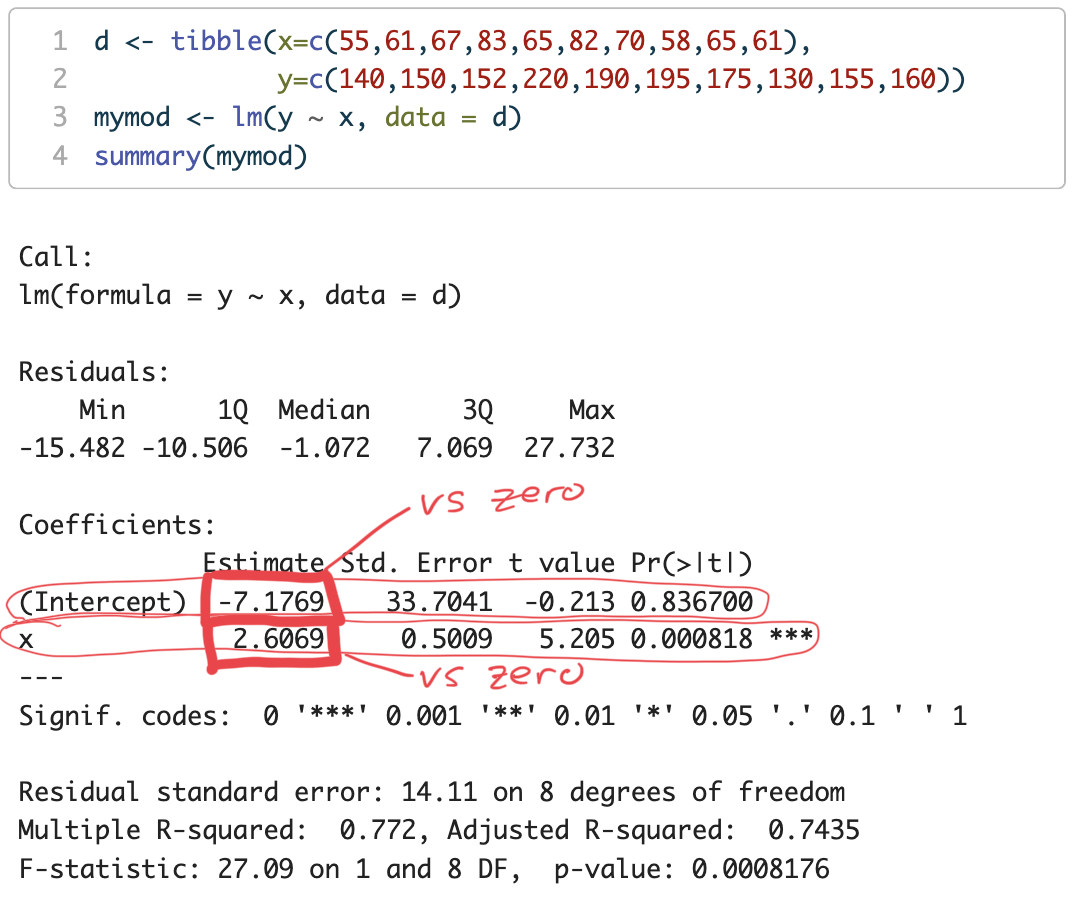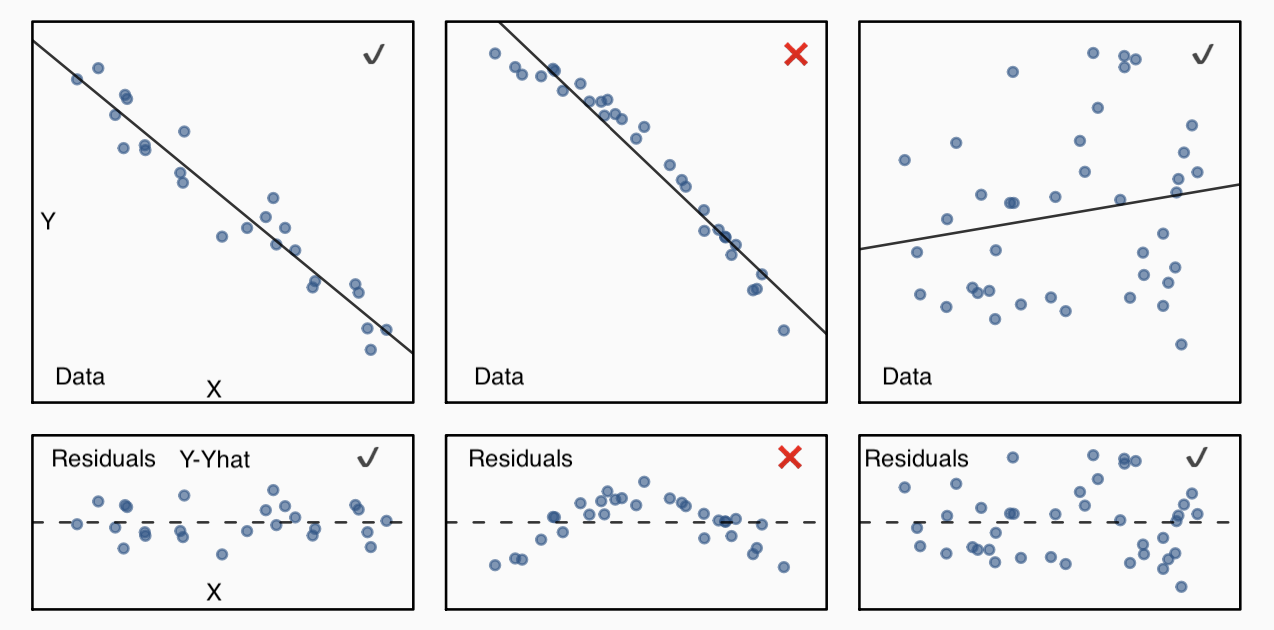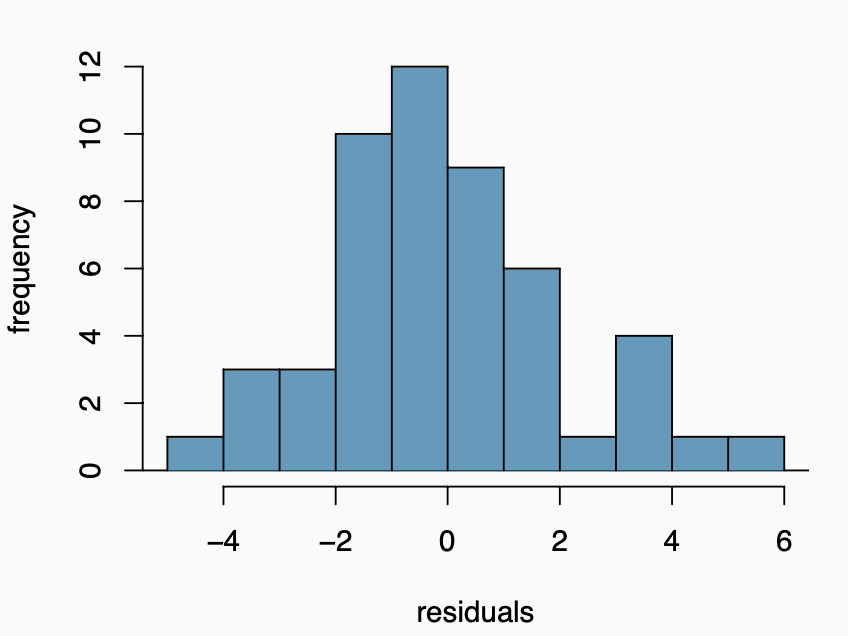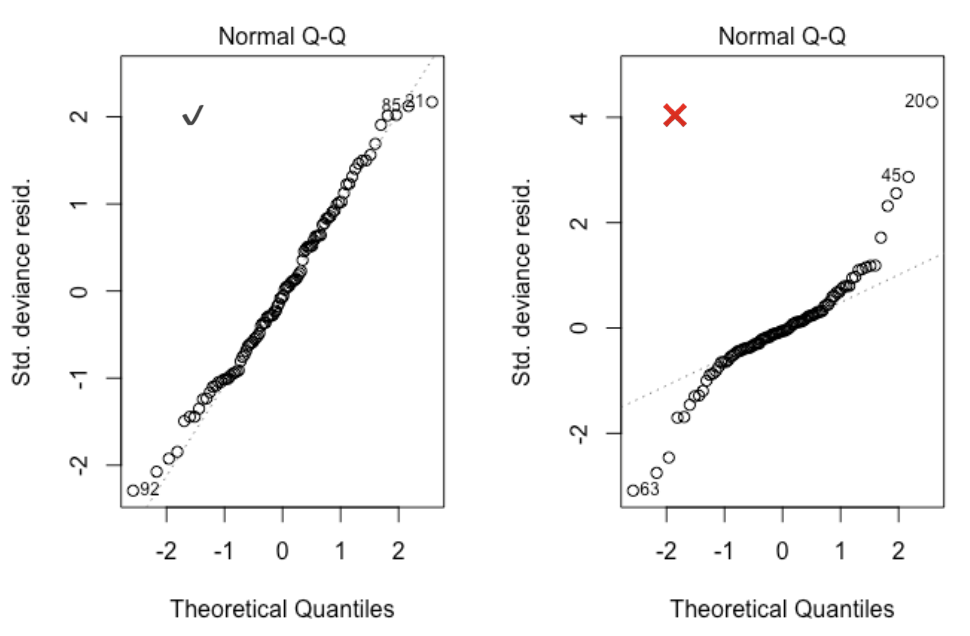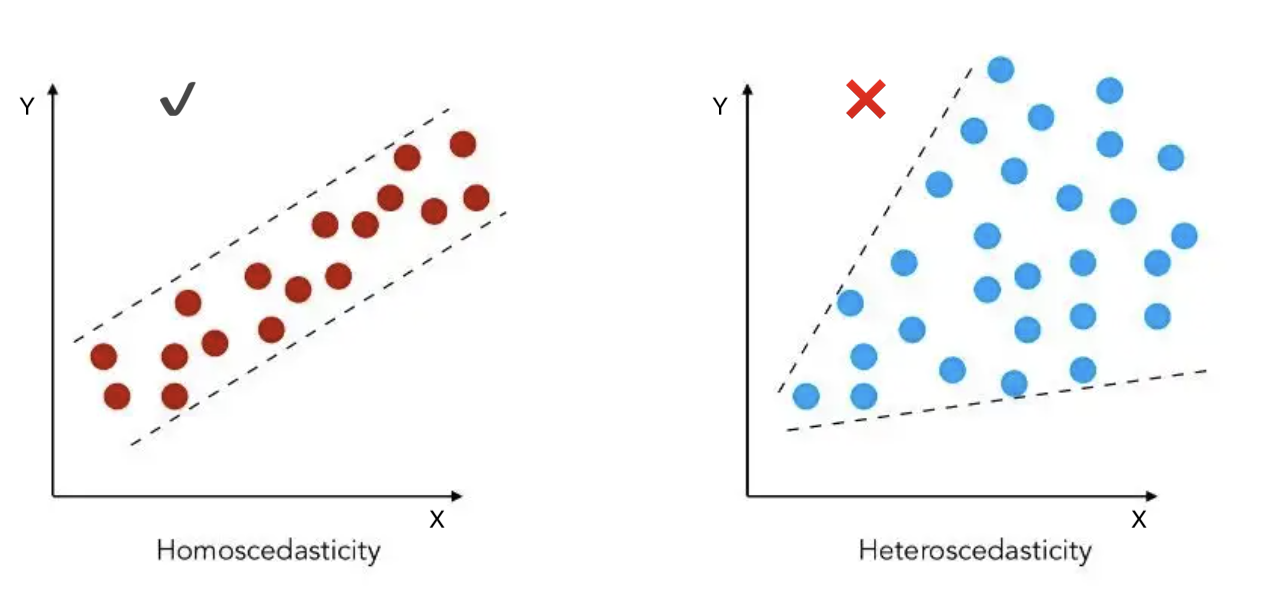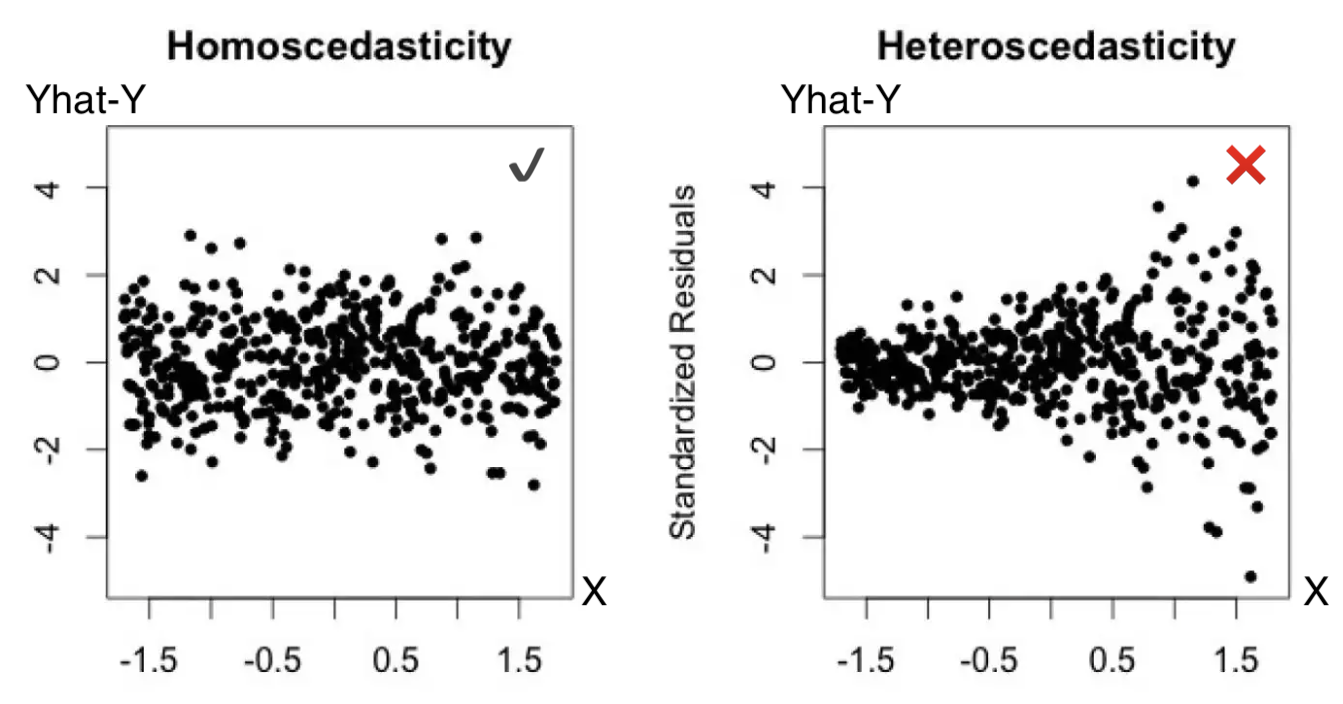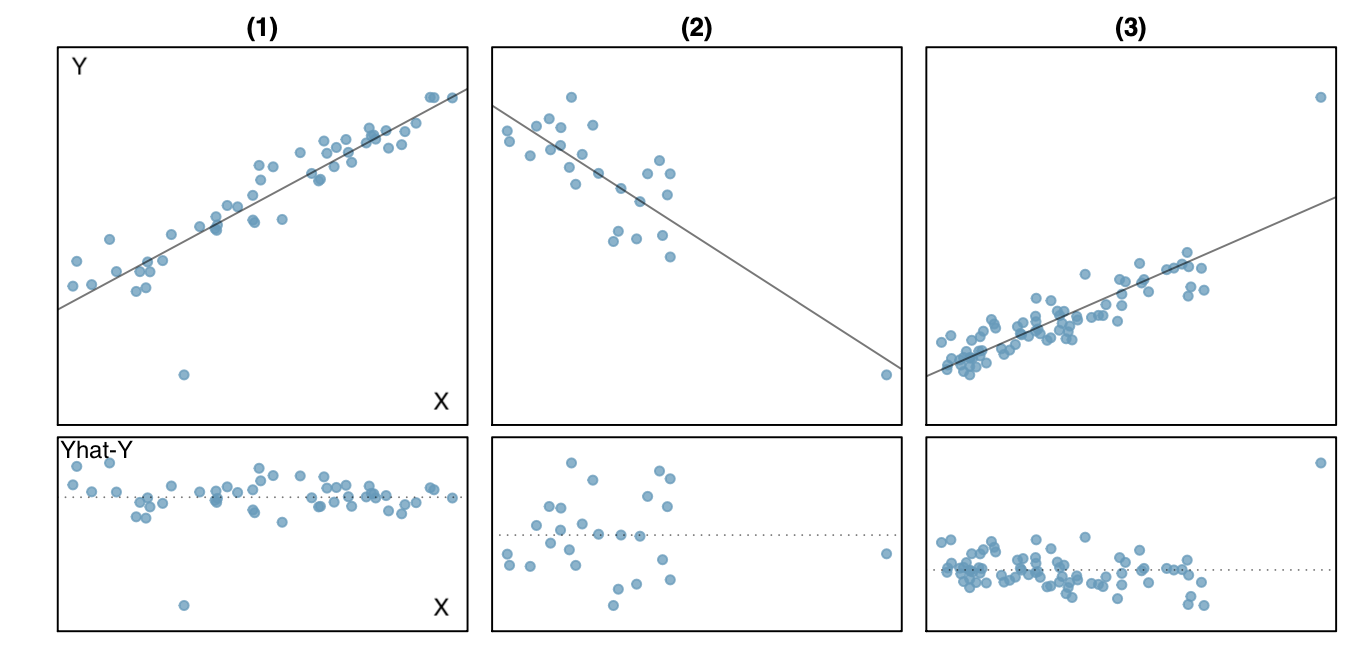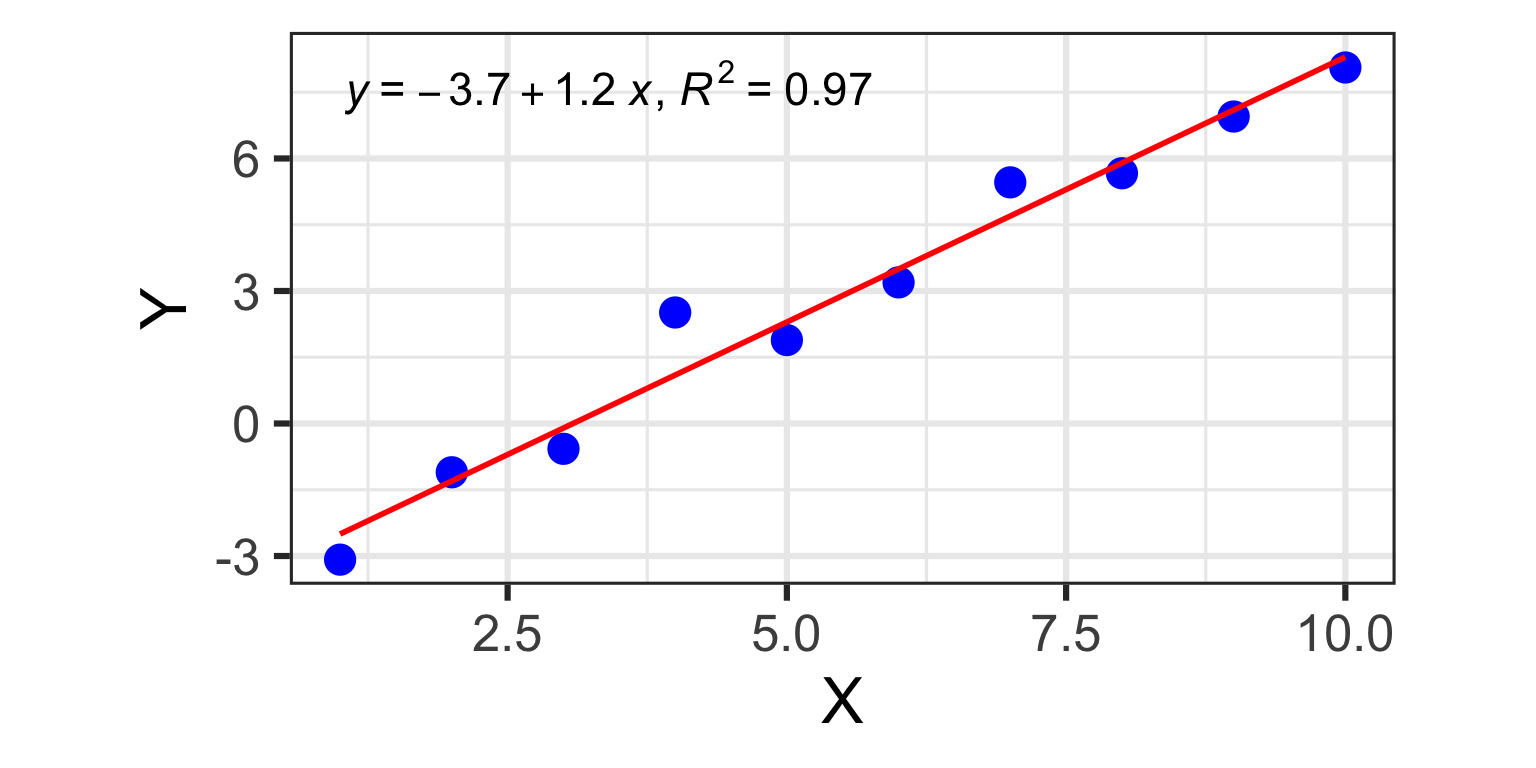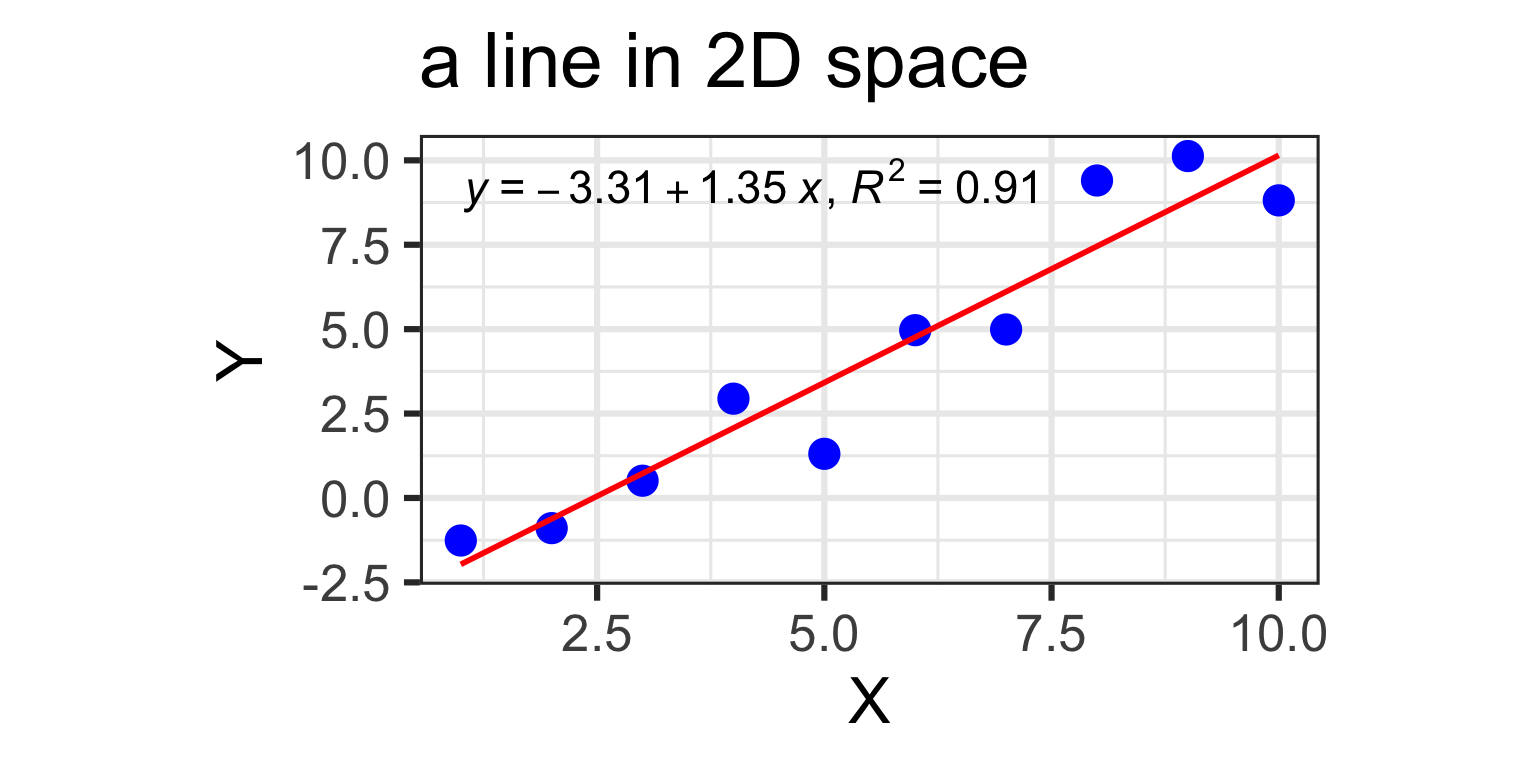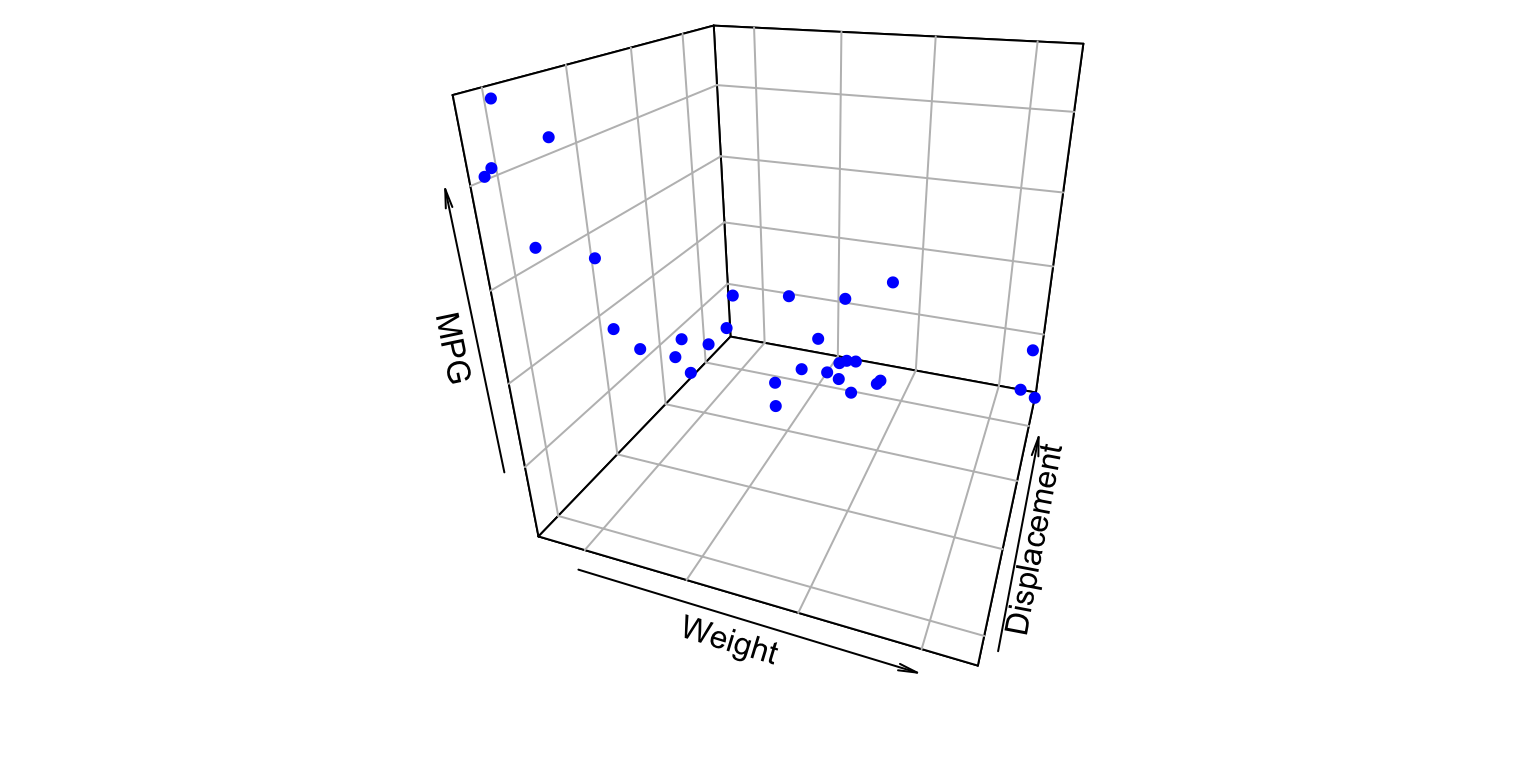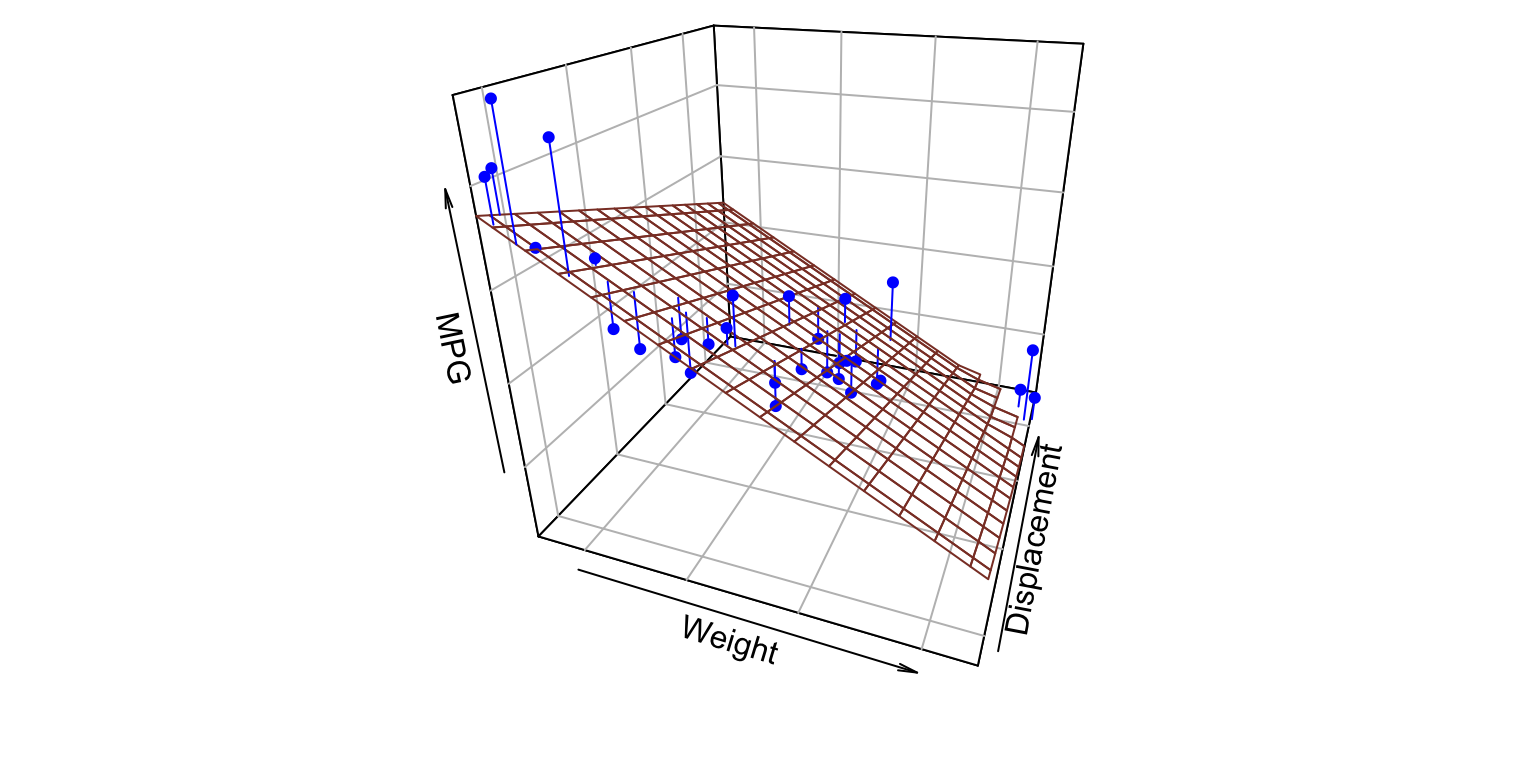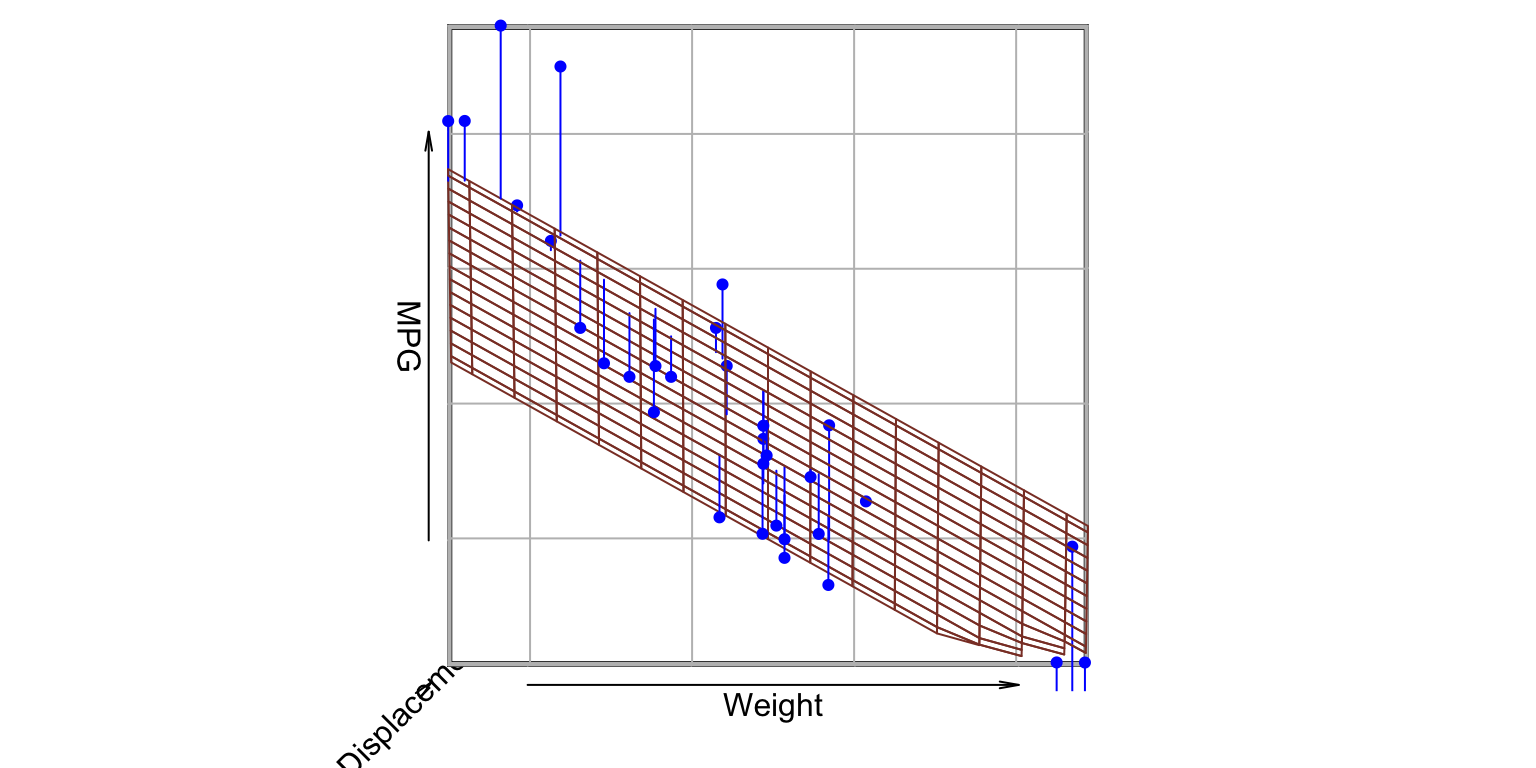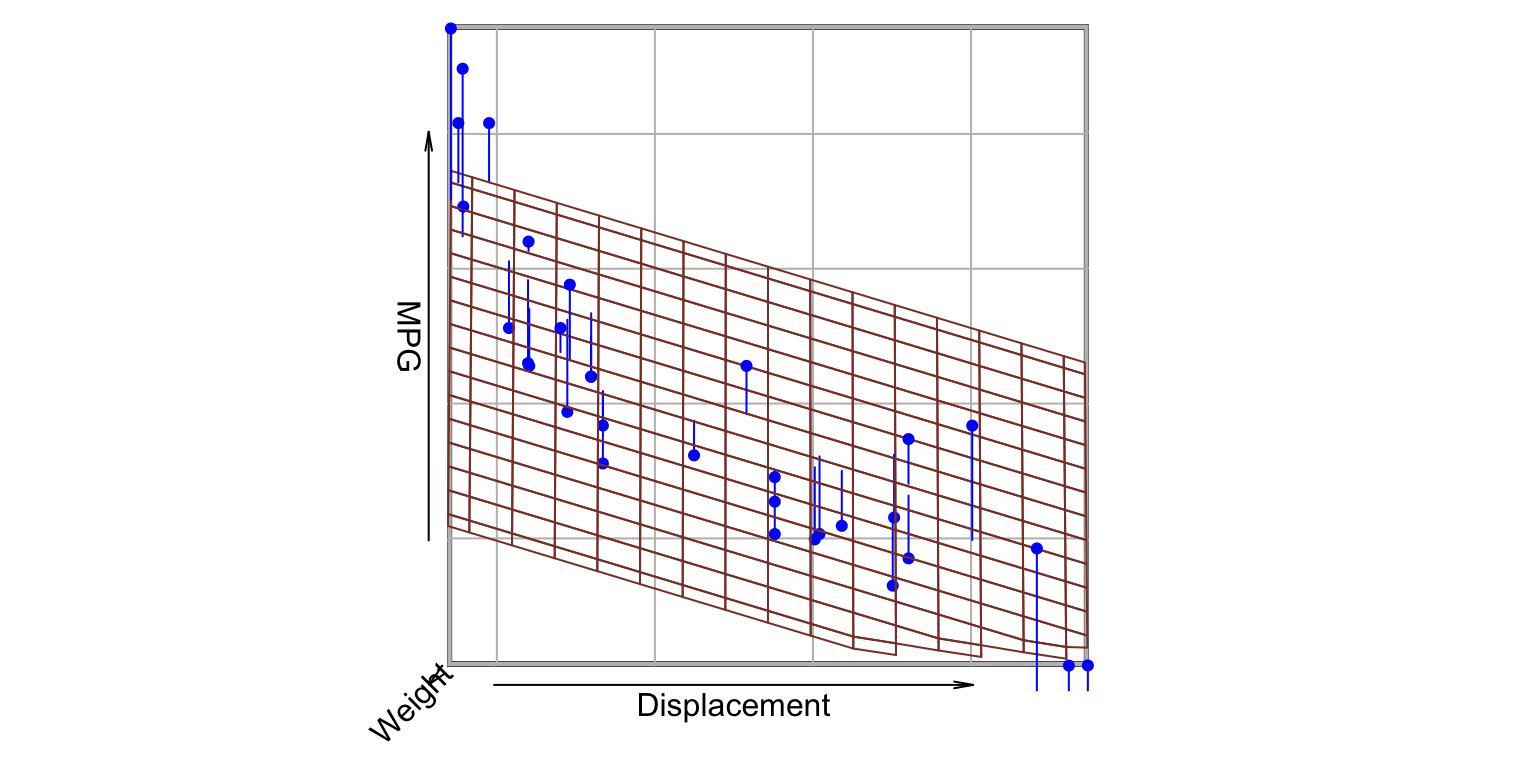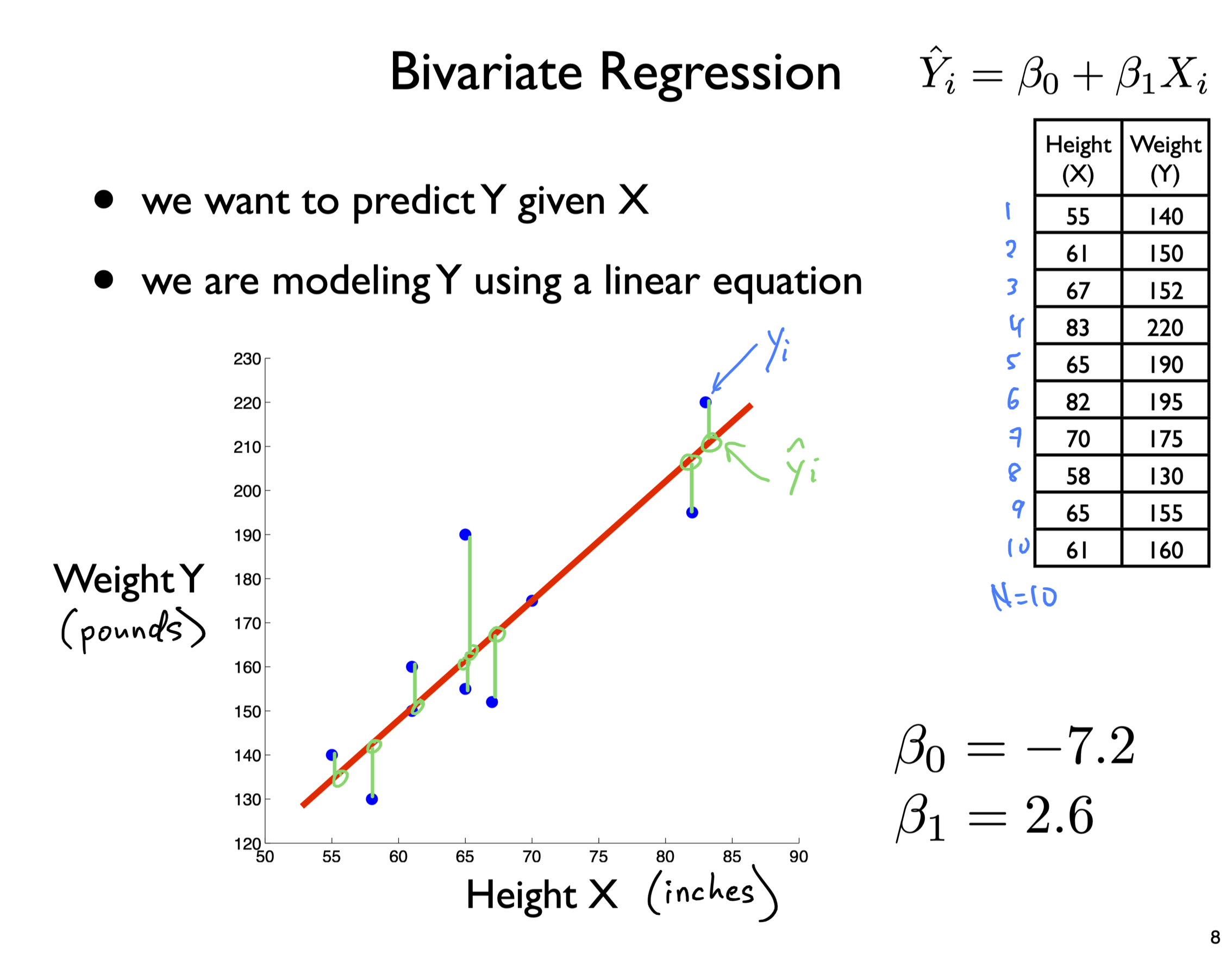
library(tidyverse)
x <- c(55,61,67,83,65,82,70,58,65,61)
y <- c(140,150,152,220,190,195,175,130,155,160)
df <- tibble(x,y)
df# A tibble: 10 × 2
x y
<dbl> <dbl>
1 55 140
2 61 150
3 67 152
4 83 220
5 65 190
6 82 195
7 70 175
8 58 130
9 65 155
10 61 160