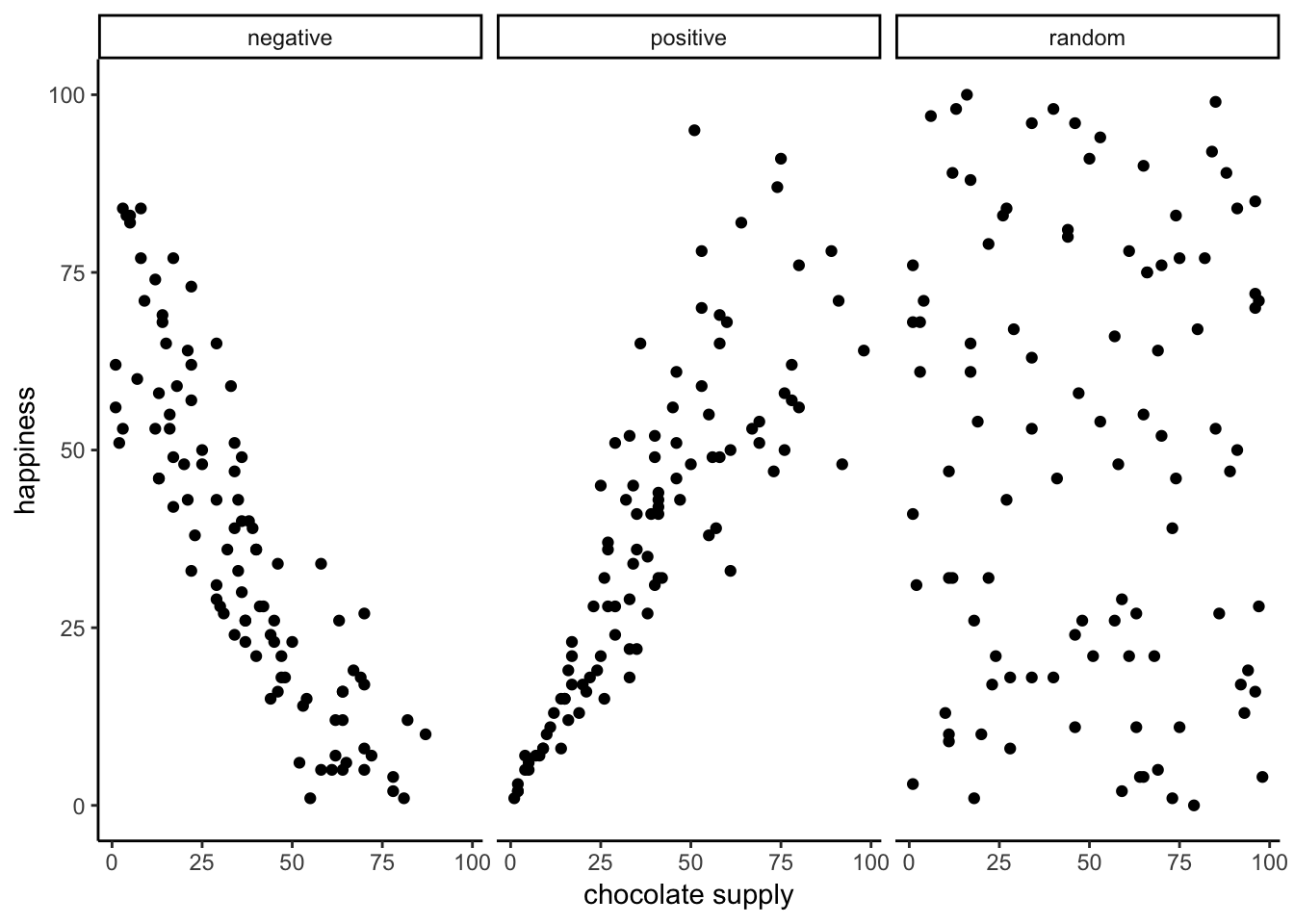
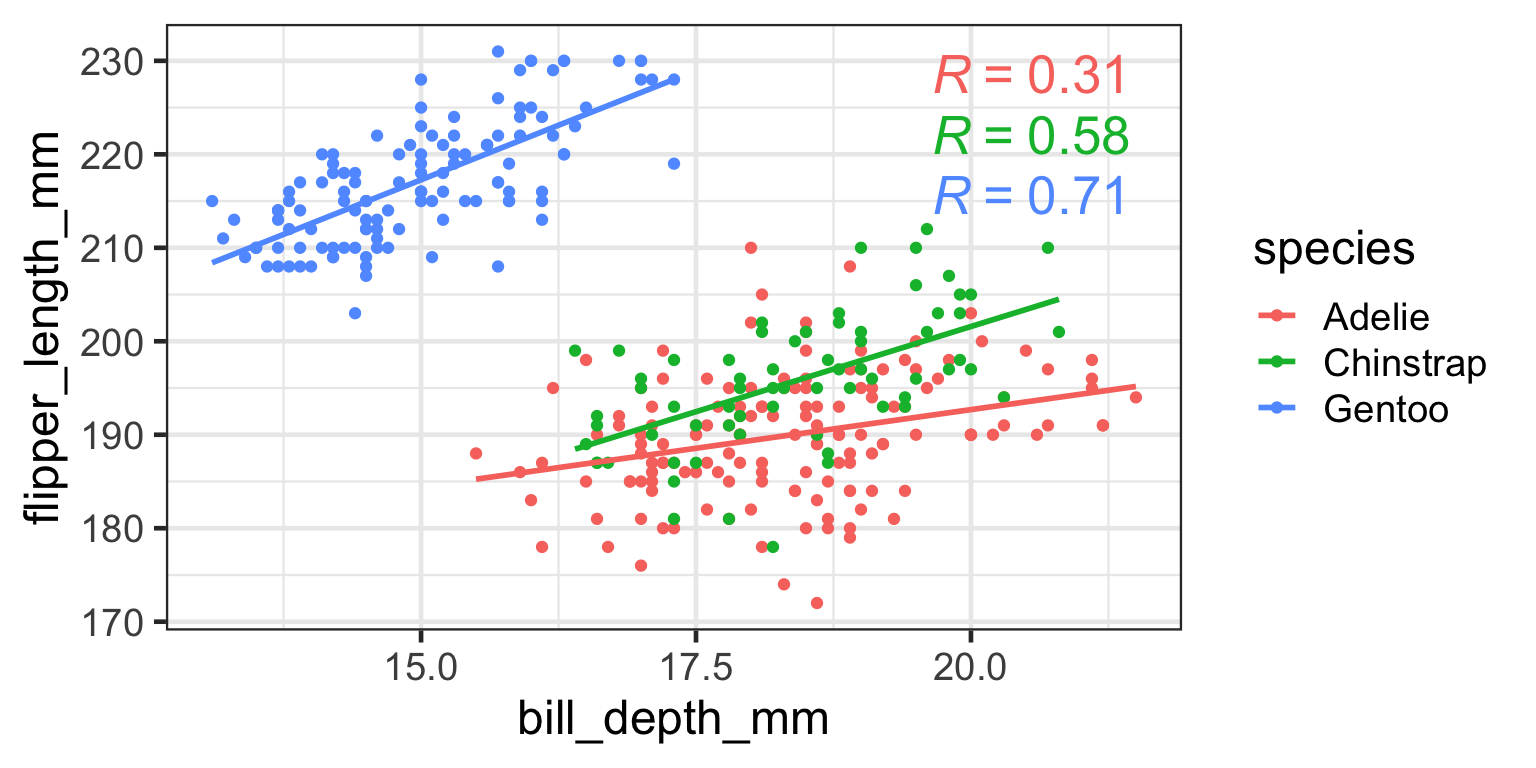
The action of the causal force can be measured by relating a measure of the cause (swing strength) to a measure of the outcome (distance travelled)
There is a positive relationship between the two measures, increasing swing strength is associated with longer distances
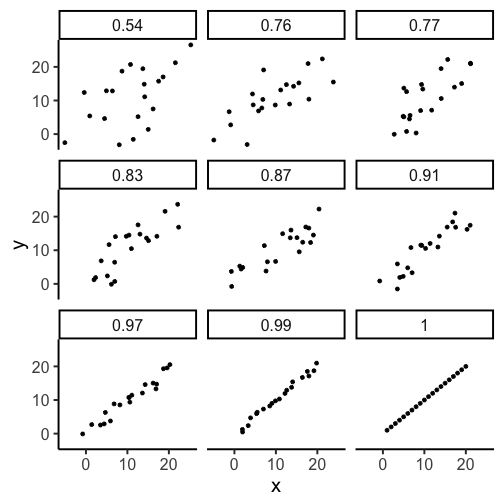
Correlation
We use the term correlation to describe the relationship between the two measures, in this case we found a positive correlation
We have seen that a causal force (swing strength) can produce a correlation between two measures
Causation & Correlation
Psychological science is interested in understanding the causes of psychological processes
We can measure change in a causal force (an indepdendent variable), and measure change in an outcome (psychological process, a dependent variable)
If the force does causally change the outcome, we expect a relationship or association between the force and the outcome (we can measure this as a correlation between the two variables)
Causation
a causal relationship between X and Y predicts a correlation between X and Y
we can test whether there’s a correlation between X and Y
if there isn’t a correlation, that argues against a causal relationship
falsification of our hypothesis
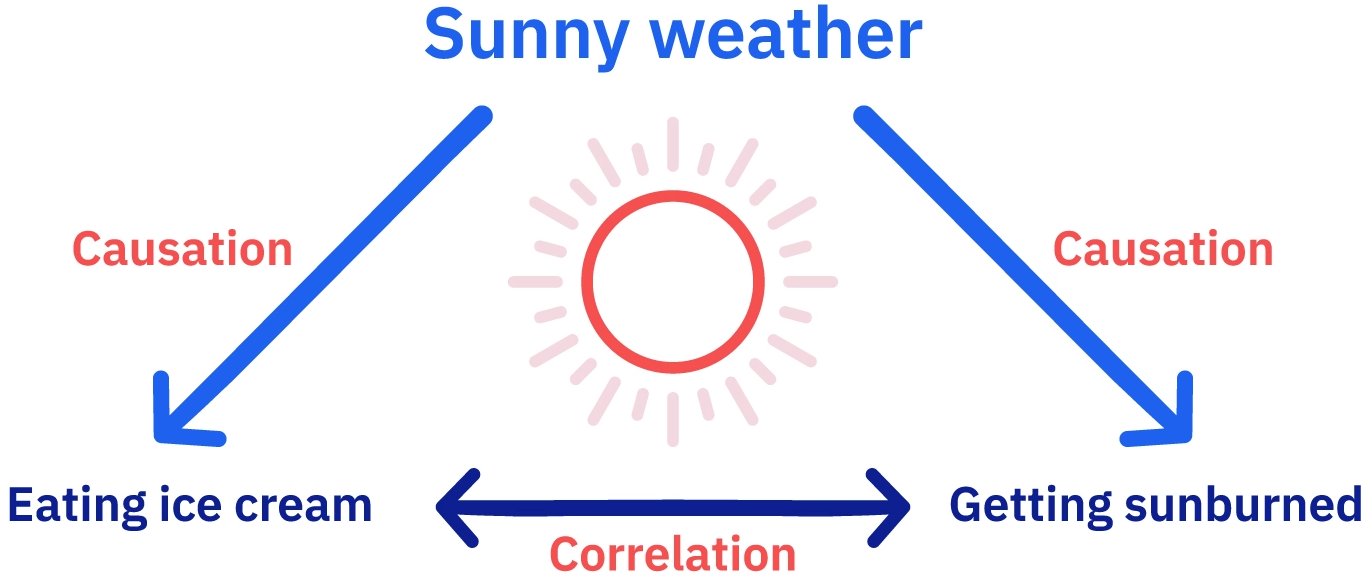
BUT the other way around doesn’t work
the observation of a correlation between X and Y does not represent evidence of a causal relationship between X and Y
Correlations between two datasets (samples from a population) can occur by chance, and be completlely meaningless
we will do some simulations!
5 Third variable
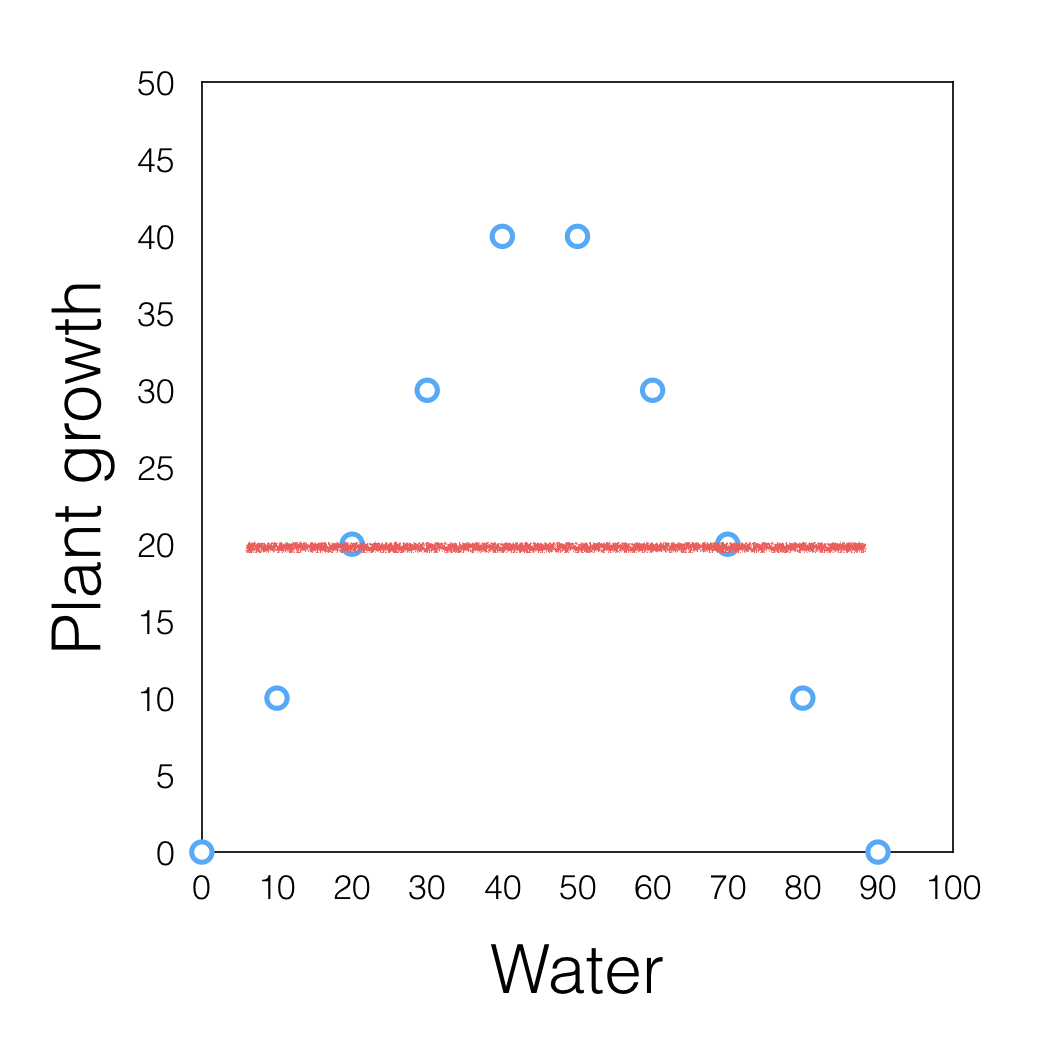
Simpson’s Paradox
a trend appears in several groups of data but disappears or reverses when the groups are combined
Simpson’s Paradox
a trend appears in several groups of data but disappears or reverses when the groups are combined
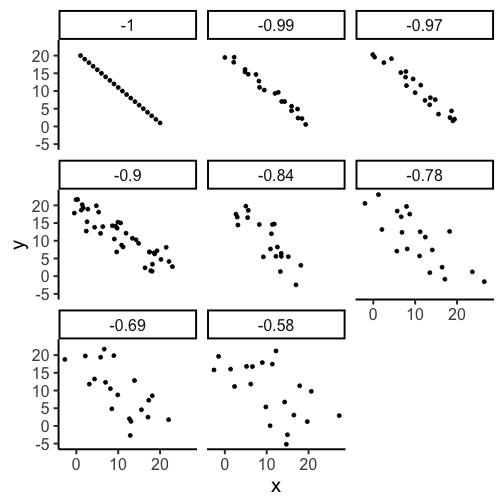
Correlation and variance
r can be between [-1,1]
r^2 is always between [0,1]
r^{2} is the proportion of variance in one variable that is explained by the other variable
r=0.5 means that 25% of the variance in one variable is explained by the other variable
r=0.1 means that only 1% of the variance in one variable is explained by the other variable
(99% of the variance is unexplained by the other variable)
Correlations and Random Chance
What is randomness?
Two related ideas:
Things have equal chance of happening (e.g., a coin flip)
50% heads, 50% tails
Correlations and Random Chance
What is randomness?
Two related ideas:
Independence: One thing happening is totally unrelated to whether another thing happens
the outcome of one flip doesn’t predict the outcome of another
Two random variables
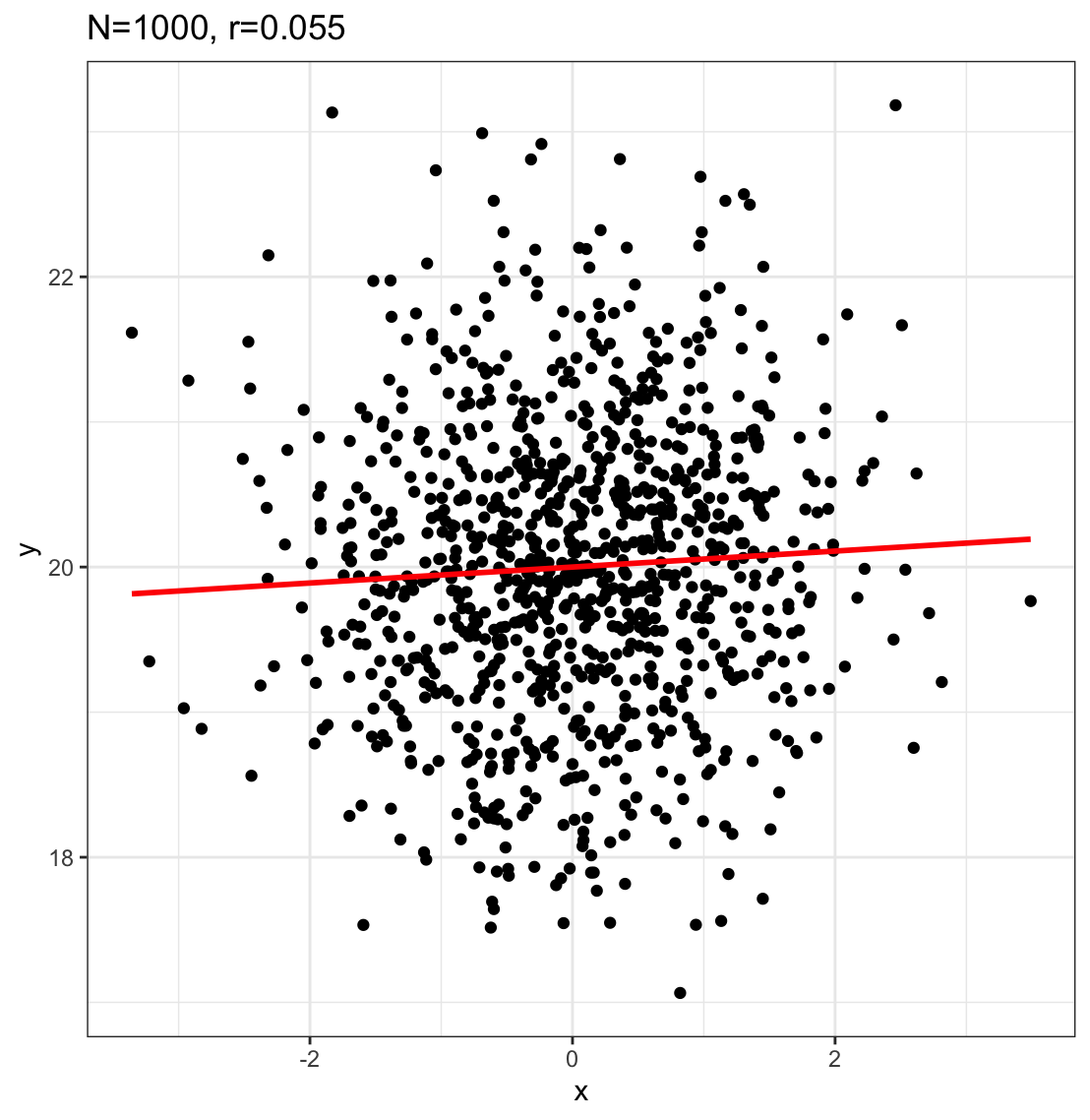
On average there should be zero correlation between two variables containing randomly drawn numbers
The numbers in variable X are drawn randomly (independently), so they do not predict numbers in Y
The numbers in variable Y are drawn randomly (independently), so they do not predict numbers in X
Two random variables
If X can’t predict Y, then correlation should be 0 right?
on average yes
for individual samples, no!
R: random numbers
In R, runif() allows you to sample random numbers (uniform distribution) between a min and max value. Numbers in the range have an equal chance of occuring
Randomly sampling numbers can produce a range of correlations, even when the actual correlation in the population is zero
What is the average correlation produced by chance? (zero)
For a single sample, what is the range of correlations that chance can produce?
answer: it depends on the sample size
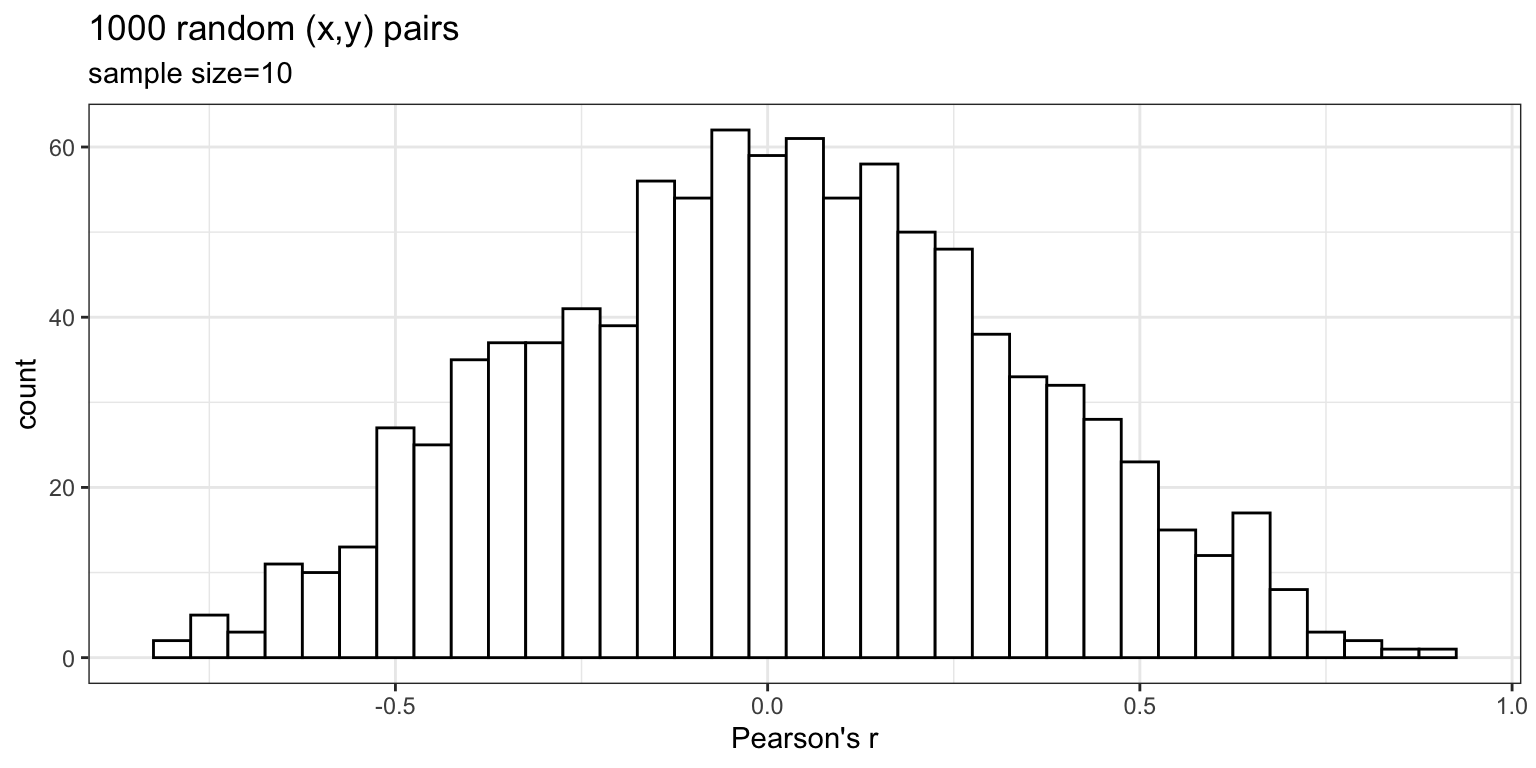
Simulating what chance can do
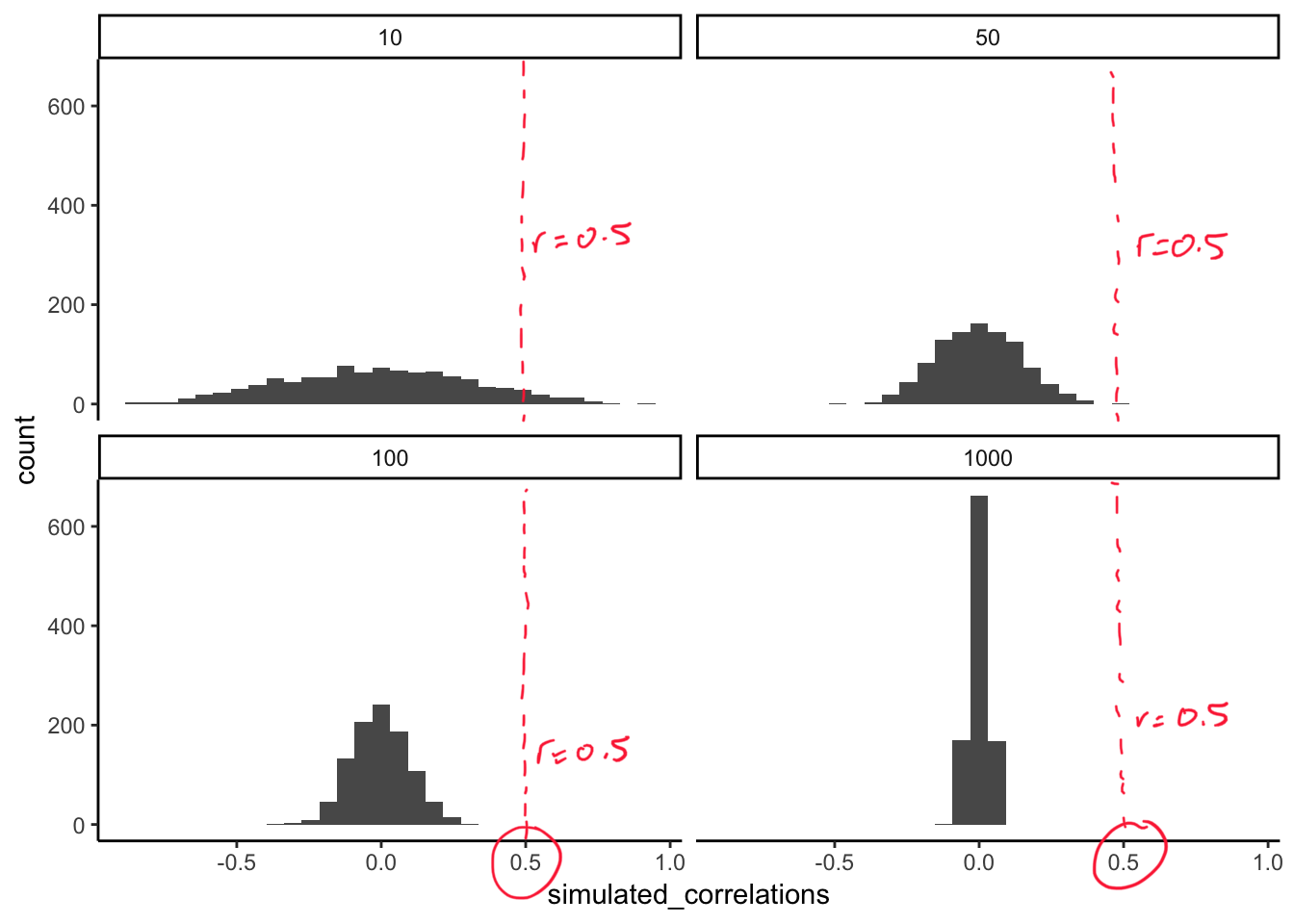
The role of sample size (N)
The range of chance correlations decreases as N increases
The inference problem
Let’s say we sampled some data, and we found r = 0.5
BUT: We know chance can sometimes produce random correlations in a sample
The inference problem
Is the correlation we observed in our sample a reflection of a real correlation in the population?
Is one variable really related to the other?
Or, is there really no correlation between these variables?
i.e. the correlation in the sample arises from random chance
→ this is H_{0}, the null hypothesis
The (simulated) Null Hypothesis
Making inferences about chance
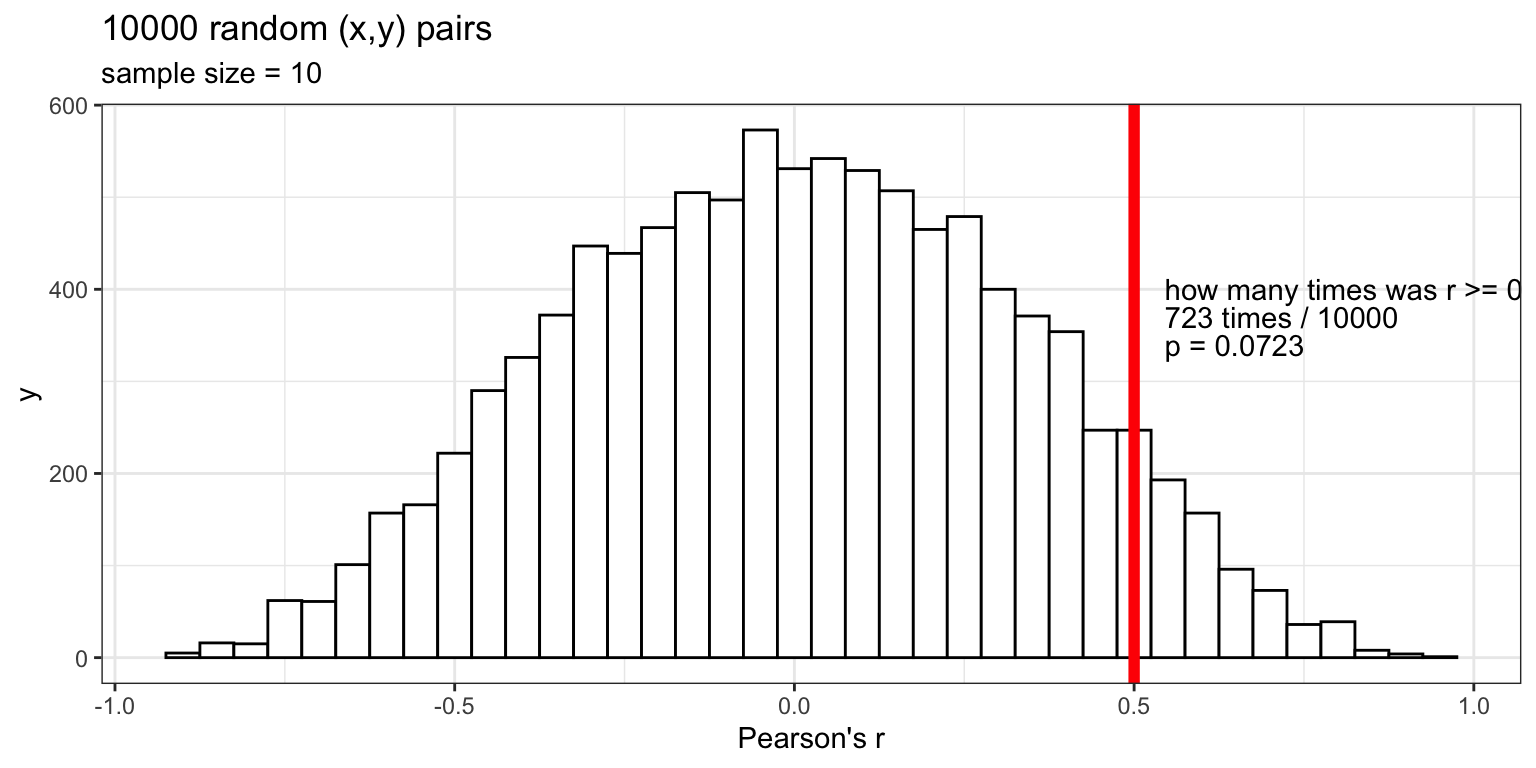
In a sample of size N=10, we observe: r=0.5
Null Hypothesis H_{0}:
→ no correlation actually exists in the population
→ actual population correlation r=0.0
Alternative Hypothesis H_{1}: correlation does exist in the population, and r=0.5 is our best estimate
We don’t know what the truth actually is
Making inferences about chance
We can only make an inference based on:
What is the probability p of observing:
→ an r in a sample as big as r=0.5
→ in a sample of size N=10
→ under the null hypothesis H_{0} in which the populationr=0.0
Making inferences about chance
If that probability p is low enough:
→ we conclude that it is an unlikely scenario
→ and we reject H_{0}
Making inferences about chance
How low can you go?
If that probability p is low enough:
→ we conclude that it is an unlikely scenario
→ and we reject H_{0}
How low is low enough?
p < .05
p < .01
p < .001
Making inferences about chance
cor.test() in R will give you the probability p of obtaining a sample correlation as large as you did under the null hypothesis where the population correlation is actually zero
Assumptions:
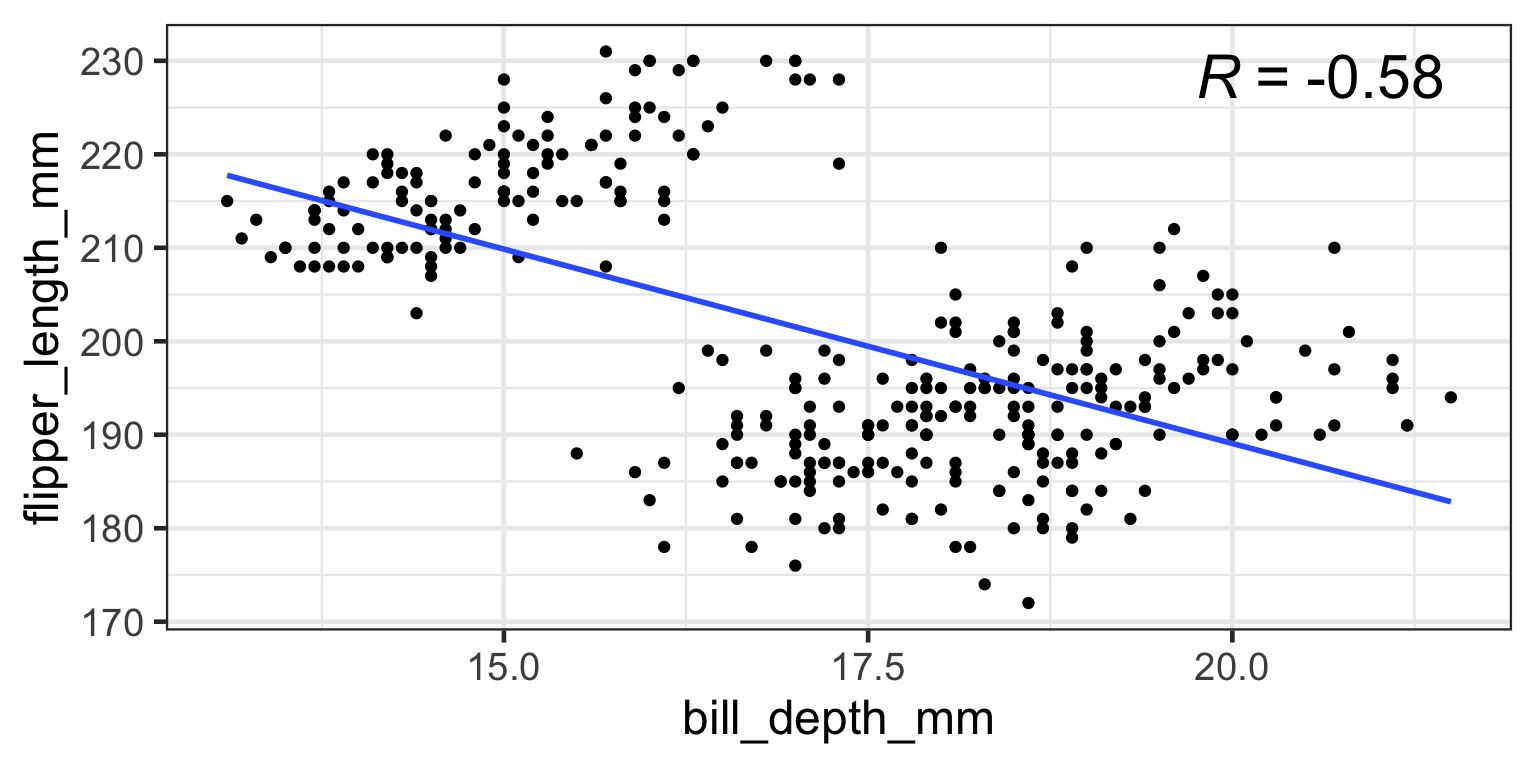
→ x vs y is a linear relationship (plot it!)
→ x & y variables are normally distributed (shapiro.test())
Shapiro-Wilk normality test
data: x
W = 0.93812, p-value = 0.01136
shapiro.test(y)
Shapiro-Wilk normality test
data: y
W = 0.96352, p-value = 0.1248
Making inferences about chance
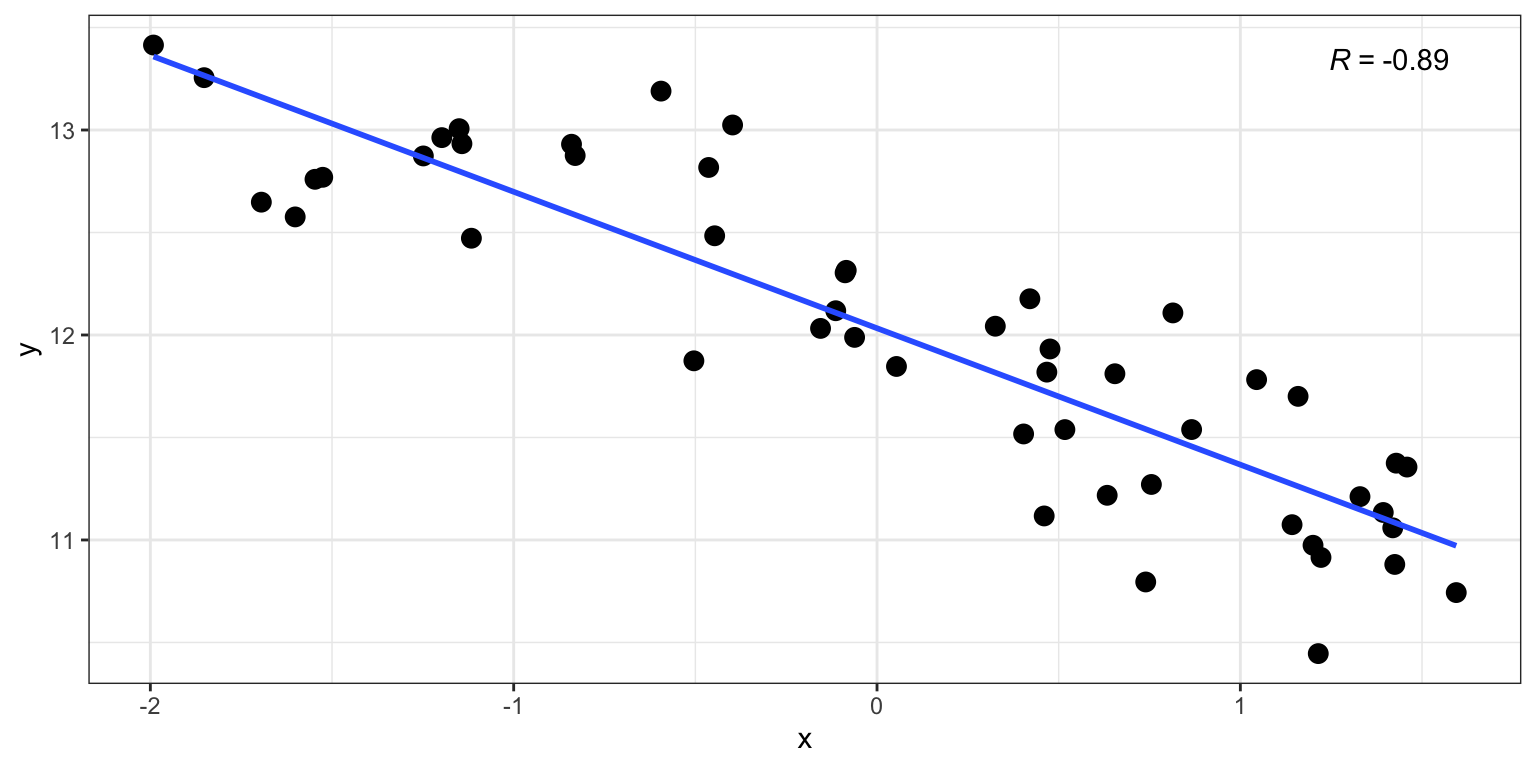
cor.test(x, y)
Pearson's product-moment correlation
data: x and y
t = -13.576, df = 48, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9368052 -0.8142478
sample estimates:
cor
-0.8907193
Making inferences about chance
if normality assumption is not met, you can use Spearman’s rank correlation coefficient \rho (“rho”)
See Chapter 5.7.6 of Navarro “Learning Statistics with R”
cor.test(x, y, method="spearman")
Spearman's rank correlation rho
data: x and y
S = 39276, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
-0.8860024



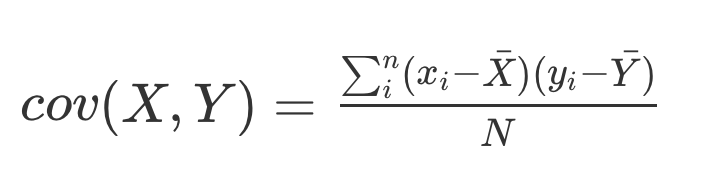



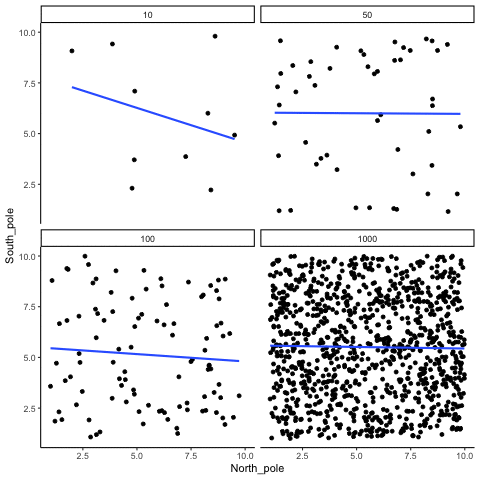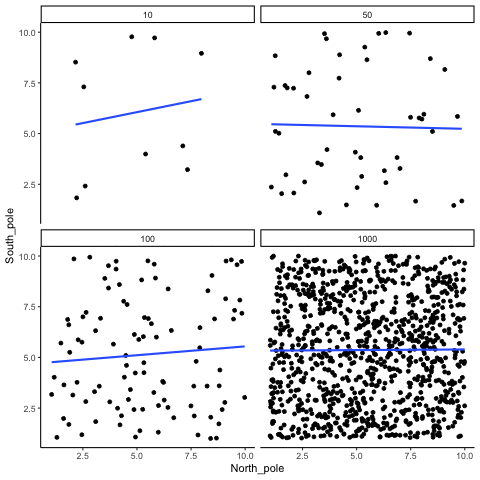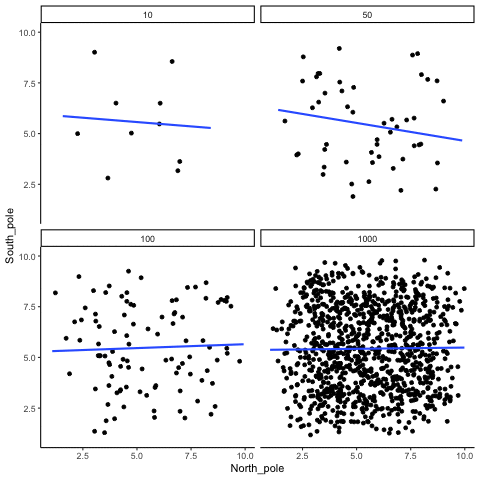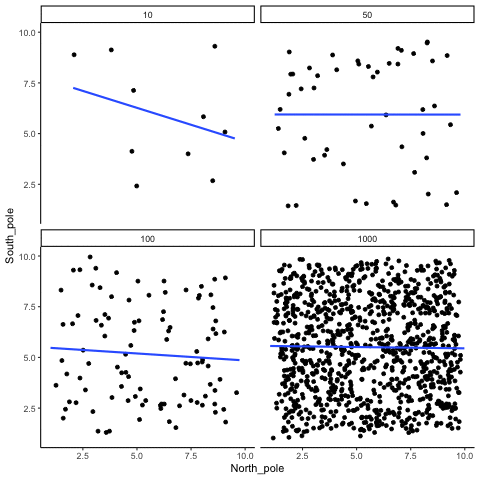
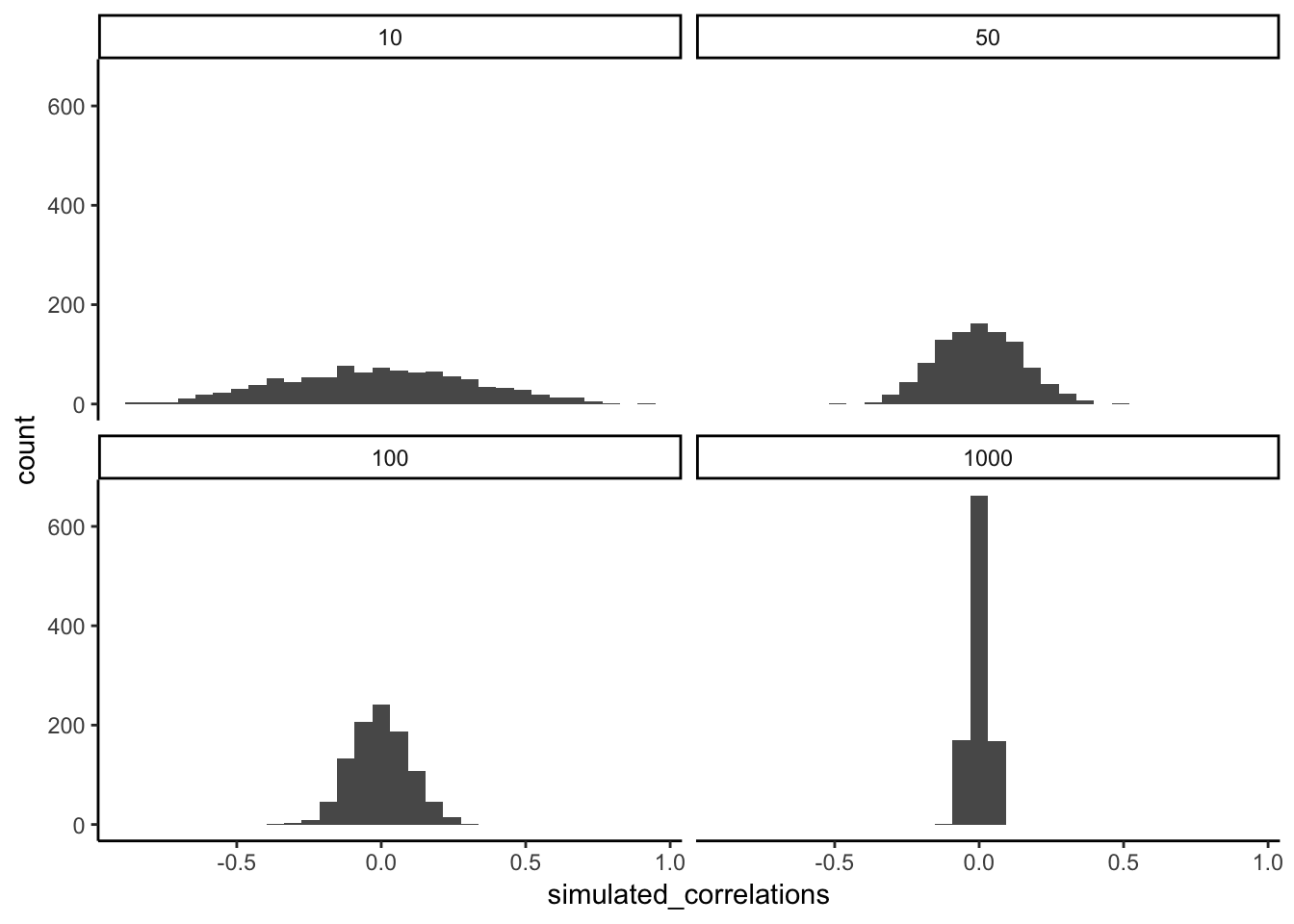 The range of chance correlations decreases as N increases
The range of chance correlations decreases as N increases